NIST Technical Series Publication
NIST SP 1500-18r2
NIST SP 1500-18r2
NIST Research Data Framework (RDaF)
Version 2.0
Robert J. Hanisch
Office of Data and Informatics
Material Measurement Laboratory
Debra L. Kaiser
Office of Data and Informatics
Material Measurement Laboratory
Alda Yuan
Office of Data and Informatics
Material Measurement Laboratory
Andrea Medina-Smith
Office of Data and Informatics
Material Measurement Laboratory
Bonnie C. Carroll
Consultant
Eva M. Campo
Consultant
Campostella Research and Consulting
Alexandria, VA
This publication is available free of charge
https://doi.org/10.6028/NIST.SP.1500-18r2
February 2024
Abstract
The NIST Research Data Framework (RDaF) is a multifaceted and customizable tool that aims to help shape the future of open data access and research data management (RDM). The RDaF will allow organizations and individual researchers to develop their own RDM strategy. Though NIST is leading the RDaF, most of the content in the current version 2.0, which supersedes preliminary V1.0 and interim V1.5, was obtained via engagement with national and international leaders in the research data community. NIST held a series of three plenary and 15 stakeholder workshops from October 2021 to September 2023. Workshop attendees represented many stakeholder sectors: US government agencies, national laboratories, academia, industry, non-profit organizations, publishers, professional societies, trade organizations, and funders (public and private), including international organizations. The audience for the RDaF is the entire research data community in all disciplines—the biological, chemical, medical, social, and physical sciences and the humanities. The RDaF is applicable from the organization to the project level and encompasses a wide array of job roles involving RDM, from executives and Chief Data Officers to publishers, funders, and researchers. The RDaF is a map of the research data space that uses a lifecycle approach with six stages to organize key information concerning RDM and research data dissemination. Through a community-driven and in-depth process, NIST identified and defined specific, high-priority topics and subtopics for each lifecycle stage. The topics and subtopics are programmatic and operational activities, concepts, and other important factors relevant to RDM which form the foundation of the framework. This foundation enables organizations and individual researchers to use the RDaF for self-assessment of their RDM status. Each subtopic has several informative references—resources such as guidelines, standards, and policies—to help a user understand or implement that subtopic. As such, the RDaF may be considered a “best practices” document. Fourteen overarching themes—topic areas identified as pervasive throughout the framework—illustrate the connections among the six lifecycle stages. Finally, the RDaF includes eight sample profiles for common job functions or roles. Each profile contains topics and subtopics an individual in the given role needs to consider in fulfilling their RDM responsibilities. Individual researchers and organizations involved in the research data lifecycle will be able to tailor these sample profiles or generate entirely new profiles for their specific job function. The methodologies used to generate the content of this publication, RDaF V2.0, are described in detail. An interactive web application has been developed and released that provides an interface for all the components of the RDaF mentioned above and replicates this document. The web application is easy and intuitive to navigate and provides new functionality enabled by the interactive environment.
Disclaimer
Publications in the SP1500 subseries are intended to capture external perspectives related to NIST standards, measurement, and testing-related efforts. These external perspectives can come from industry, academia, government, and others. These reports are intended to document external perspectives and do not represent official NIST positions. The opinions, recommendations, findings, and conclusions in this publication do not necessarily reflect the views or policies of NIST or the United States Government.
Certain commercial entities, equipment, or materials may be identified in this document to describe an experimental procedure or concept adequately. Such identification is not intended to imply recommendation or endorsement by NIST, nor is it intended to imply that the entities, materials, or equipment are necessarily the best available for the purpose.
NIST Technical Series Policies
Copyright, Fair Use, and Licensing Statements
NIST Technical Series Publication Identifier Syntax
Publication History
Approved by the NIST Editorial Review Board on 2023-12-21
Supersedes NIST Series 1500-18 version 1.5 (May 2023) https://doi.org/10.6028/NIST.SP.1500-18r1; NIST Series 1500-18 (February 2021) https://doi.org/10.6028/NIST.SP.1500-18
How to Cite this NIST Technical Series Publication
Hanisch, RJ; Kaiser, D; Yuan, A; Medina-Smith, A; Carroll, B; Campo, E (2023) NIST Research Data Framework (RDaF) Version 2.0. (National Institute of Standards and Technology, Gaithersburg, MD), NIST Special Publication (SP) 1500-18r2. https://doi.org/10.6028/NIST.SP.1500-18r2
NIST Author ORCID IDs
Robert Hanisch: 0000-0002-6853-4602
Debra Kaiser: 0000-0001-5114-7588
Alda Yuan: 0000-0001-9619-306X
Andrea Medina-Smith: 0000-0002-1217-701X
Bonnie Carroll: 0000-0001-8924-1000
Eva Campo: 0000-0002-9808-4112
Contact Information
Foreword
Version 2.0 of the NIST Research Data Framework builds on the Preliminary version 1.0 released in February 2021 and on the interim version 1.5 released in May 2023, and incorporates input from many stakeholders. Version 2.0 has more than twice as many topics and subtopics as V1.0 and includes new sections. The major new sections are overarching themes: terms prevalent in multiple lifecycle stages, and profiles, which provide a list of the most relevant topics and subtopics for a given job function or role within the research data management ecosystem. A Request for Information (RFI) based on interim V1.5 was posted in the Federal Register in early June 2023. All comments received in response to this RFI were considered and the RDaF V1.5 was revised as appropriate. A draft of this modified version was presented at a stakeholder workshop held in September 2023.
Author Contributions
Robert Hanisch: Conceptualization, Methodology, Supervision, Writing- review and editing; Debra Kaiser: Formal Analysis, Methodology, Writing- review and editing; Alda Yuan: Formal Analysis, Methodology, Project Administration, Writing- original draft, Writing- review and editing, Visualization; Andrea Medina-Smith: Data Curation, Formal Analysis, Visualization, Software, Writing- review and editing; Bonnie Carroll: Conceptualization, Supervision, Writing- review and editing; Eva M. Campo: Data Curation, Visualization, Writing- review and editing.
Acknowledgments
The completeness, relevance, and success of the NIST RDaF is wholly dependent on the input and participation of the broad research data community. NIST is grateful to all the workshop participants and others who have provided input to this effort. First and foremost, NIST thanks the members of the RDaF Steering Committee, past and present, who have given sound advice and shared their invaluable expertise since the inception of the RDaF in December 2019: Laura Biven, Cate Brinson, Bonnie Carroll (Chair), Mercè Crosas, Anita de Waard, Chris Erdmann, Joshua Greenberg, Martin Halbert, Hilary Hanahoe, Heather Joseph, Mark Leggott, Barend Mons, Sarah Nusser, Beth Plale, and Carly Strasser.
The RDaF team is also grateful to Susan Makar from the NIST Research Library for assistance with the informative references and to Angela Lee for development of the V2.0 interactive web application. Thanks to Eric Lin and James St. Pierre for their critical advice.
Thanks to the former members of the RDaF team including Breeze Dorsey, Laura Espinal, and Tamae Wong. Thanks as well to Campostella Research and Consulting for providing administrative support for the project and technical support for the natural language processing work. Our appreciation also goes to the NIST Material Measurement Laboratory (MML) leadership for their support and to all participants of the various workshops held to solicit community feedback, particularly those individuals who volunteered to serve as discussion leaders.
And finally, thanks to all involved with the NIST Cybersecurity Framework, which provided an initial model for development of the RDaF.
Keywords Research data, research data ecosystem, research data framework, research data lifecycle, research data management, research data dissemination, use, and reuse, research data governance, research data sharing, research data stewardship, open data.
1 Introduction
NIST’s Research Data Framework (RDaF) is designed to help shape the future of research data management (RDM) and open data access. Research data are defined here as “the recorded factual material commonly accepted in the scientific community as necessary to validate research findings.”[1] The motivation for the RDaF as articulated in the first RDaF publication V1.0 [2]—that the research data ecosystem is complicated and requires a comprehensive approach to assist organizations and individuals in attaining their RDM goals—has not changed since the project was initiated in 2019. Developed through active involvement and input from national and international leaders in the research data community, the RDaF provides a customizable strategy for the management of research data. The audience for the RDaF is the entire research data community, including all organizations and individuals engaged in any activities concerned with RDM, from Chief Data Officers and researchers to publishers and funders. The RDaF builds upon previous data-focused frameworks but is distinct through its emphasis on research data, the community-driven nature of its formulation, and its broad applicability to all disciplines, including the social sciences and humanities.
The RDaF is a map of the research data space that uses a lifecycle approach with six high-level lifecycle stages to organize key information concerning RDM and research data dissemination. Through a community-driven and in-depth process, stakeholders identified topics and subtopics—programmatic and operational activities, concepts, and other important factors relevant to RDM. These topics and subtopics, identified via stakeholder input, are nested under the six stages of the research data lifecycle. A partial example of this structure is illustrated in Fig. 1.
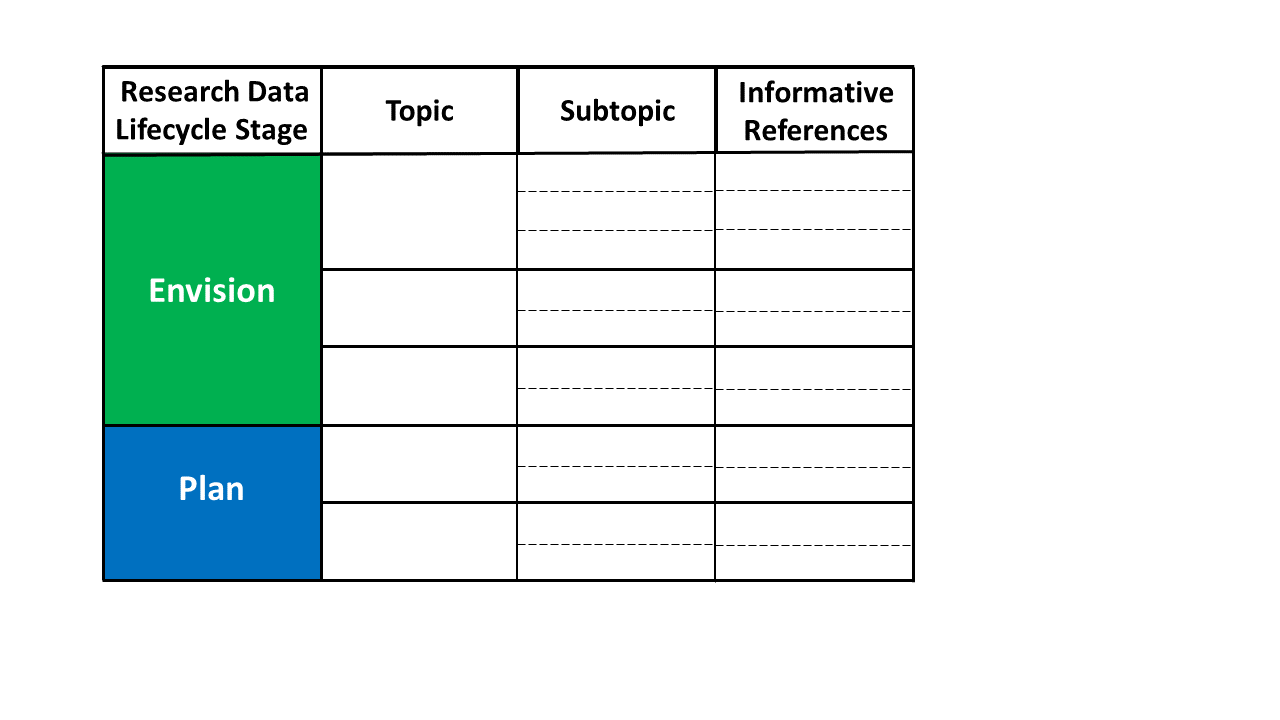
Fig. 1 — Partial organizational structure of the framework foundation
The components of the RDaF foundation shown in Fig. 1—lifecycle stages and their associated topics and subtopics—are defined in this document. In addition, most subtopics have several informative references—resources such as guidelines, standards, and policies—that assist stakeholders in addressing that subtopic. Specific standards and protocols provided in the text or informative references may only be relevant for certain RDM situations. A link to the complete list of informative references is given in Appendix A.
The RDaF is not prescriptive; it does not instruct stakeholders to take any specific approach or action. Rather, the RDaF provides stakeholders with a structure for understanding the various components of RDM and for selecting components relevant to their RDM goals. The RDaF also includes sample profiles, which contain topics and subtopics an individual in a job role or function are encouraged consider in fulfilling their RDM responsibilities. Researchers and organizations involved in the research data lifecycle will be able to tailor these profiles using a supplementary document and online tools that will be available on the RDaF homepage. Entirely new profiles may be generated using a blank on-line template available in this supplementary document. Other uses of the RDaF include self-assessment and improvement of RDM infrastructure and practices for both organizations and individuals.
The RDaF was designed to be applicable to all stakeholders involved in research data. An organization seeking to review their data management policies may use the subtopics to create their own metrics for RDM assessment. Researchers who wish to ensure that their data are open access may use the framework to create a “checklist” of RDM considerations and tasks. A research project leader seeking guidance on how to assign data management roles may use the eight sample profiles as a starting point to create customized lists of responsibilities for individual researchers in their lab.
Since the first publication of the RDaF in 2021 (V1.0 [2]), NIST has expanded and enriched the framework through extensive engagement with stakeholders in the research data community. This publication, RDaF V2.0, includes updates to V1.0 and new features. Definitions and informative references for each subtopic have been added to improve the usability and applicability of the RDaF. In addition to profiles discussed in the previous paragraph, this document includes overarching themes that appear across multiple lifecycle stages and a list of many of the key organizations in the RDM space (see Appendix B). The methodology used to generate the content of V2.0 is described in detail in the following section.
Note that the terms “data,” “datasets,” “data assets,” “digital objects,” and “digital data objects” are used throughout the framework depending on the context. Data is the most general and frequently used term. Dataset means a specific collection of data having related content. A data asset is “any entity that is comprised of data which may be a system or application output file, database, document, and web page.”[3] Digital objects and digital data objects typically have a structure such that they can be understood without the need for separate documentation. In addition, the terms “organization” and “institution” used throughout the framework are synonymous and the terms "RDaF team" and "team" refer to the authors of this publication. Finally, a list that spells out the full names of acronyms and initialisms used throughout this document is provided in Appendix C.
2 Methodology
This section describes the approaches used to develop RDaF V2.0, including brief descriptions of activities since the inception of the project in 2019. Throughout the lifetime of the RDaF project, the Steering Committee members noted previously in the Acknowledgements section were consulted, took leadership roles as discussion leaders at workshops, and provided valuable input and feedback on all aspects of the project.
2.1 Framework Development Through Stakeholder Input
The RDaF is driven by the research data stakeholder community, which can use the framework for multiple purposes such as identifying best practices for research data management (RDM) and dissemination and changing the research data culture in an organization. To ensure that the RDaF is a consensus document, NIST held stakeholder engagement workshops as the primary mechanism to gather input on the framework. The workshops have taken place in three phases, each resulting in further examination and refinement of the framework.
2.1.1 Phase 1: Plenary Scoping Workshop and Publication of the Preliminary RDaF V1.0
In the plenary scoping workshop held in December 2019, a group of about 50 distinguished research data experts selected a research data lifecycle approach as the organizing principle of the RDaF. The RDaF team subsequently selected six lifecycle stages—Envision, Plan, Generate/Acquire, Process/Analyze, Share/Use/Reuse, and Preserve/Discard—from a larger pool of stages suggested by workshop break-out groups. Feedback from this workshop contributed to the publication of the RDaF V1.0, which provides a structured and customizable approach to developing a strategy for the management of research data. The framework core (subsequently renamed foundation in V2.0) consisting of these six lifecycle stages and their associated topics and subtopics is the main result of that publication.
2.1.2 Phase 2: Opening Plenary Workshops
The second phase of the RDaF development began with two virtual plenary workshops held in late 2021. Each workshop had approximately 70 attendees and focused on two cohorts. The university cohort (UC) workshop, co-hosted by the Association of American Universities, the Association of Public Land-grant Universities, and the Association of Research Libraries, was a horizontal cut across various stakeholder roles in universities (e.g., vice presidents of research, deans, professors, and librarians), publishing organizations, data-based trade organizations, and professional societies. In contrast, the materials cohort (MC) workshop, held in cooperation with the Materials Research Data Alliance, was a vertical cut across stakeholder organizations engaged in materials science, including academia, government agencies, industry, publishers, and professional societies.
Prior to the workshops, the attendees selected, or were assigned to, one of six breakout sessions, each focused on a stage in the RDaF research data lifecycle. A NIST coordinator sent the attendees a link to the RDaF publication V1.0, a list of the participants, and definitions of the topics for that session’s lifecycle stage. The agenda for the two workshops included an overview talk by Robert Hanisch on the RDaF, a one-hour breakout session, and a plenary session with summaries presented by an attendee of each breakout and with closing remarks. During the breakout sessions, a discussion leader, recruited by the RDaF team, solicited input from the 10 to 12 participants on the following questions:
-
What are the most important (two or three) topics and the least important one?
-
Are there any missing topics?
-
Should any topics be modified or moved to another lifecycle stage?
The identical questions were posed regarding the subtopics for each topic. Attendee input was captured as notes taken by the session rapporteur and the NIST coordinator and an audio recording. After the two opening plenary workshops, the RDaF team revised the topics and subtopics for the lifecycle stages based on input from the workshops. All six of the lifecycle stages were then reviewed side-by-side for consistency and completeness.
The collective review revealed 14 overarching themes which appeared in multiple lifecycle stages. These themes include metadata and provenance, data quality, the FAIR (Findable, Accessible, Interoperable, and Reusable) data principles, software tools, and cost implications. Section 4 of this document will address all overarching themes in detail.
2.1.3 Phase 3: Stakeholder Workshops
The next step in obtaining community input involved a series of two-hour stakeholder workshops focused on specific roles, equivalent to job functions or position titles. To secure a broad range of feedback, the RDaF team compiled a list of more than 200 invitees, including attendees of previous workshops and additional experts. These invitees were assigned to one of the following 15 roles:
-
Academic mid-level executive/head of research
-
AI expert
-
Budget/cost expert
-
Curator
-
Data/IT leader
-
Data/research governance leader
-
Funder
-
Institute/center/program director
-
Open data expert
-
Professional society/trade organization leader
-
Professor
-
Provider of data tools/services/infrastructure
-
Publisher
-
Researcher
-
Senior executive
Unlike the first two RDaF workshops, these role-focused workshops were composed of smaller groups. The goal of these workshops was to develop profiles, i.e., lists of topics and subtopics important for individuals in a specific role with respect to RDM. Though the target size of these two-hour workshops was 10 to12 participants, the actual number ranged from four to 14. For each workshop, the RDaF team identified and invited an expert to serve as the discussion leader. Two members of the team were assigned to each workshop: a presenter and a rapporteur.
During the workshops, after a brief presentation covering the purpose and structure of the RDaF, participants selected the lifecycle stages most relevant to their assigned role. For each lifecycle stage, participants reviewed the topics and subtopics, and discussed any that were missing, misplaced or unclear. Depending on the length of the discussion, each workshop covered two to four of the lifecycle stages. In addition to requesting input on the topics and subtopics, the NIST coordinators asked participants to consider which topics and subtopics had the greatest influence on their role and those over which they had the greatest influence.
2.2 Framework Revisions per Stakeholder Workshop Input
Most of the input from participants at the Stakeholder Workshops concerned the topics and subtopics, and this input was used to revise them.
2.2.1 Stakeholder Workshop Note Aggregation
After the Stakeholder Workshops, the RDaF team designed a common methodology for collecting and analyzing the feedback, using a template to record the input from each workshop. This template contained the following:
-
A column for topics and subtopics in a lifecycle stage that were missing, misplaced, or unclear
-
A column for topics and subtopics relevant to, or missing from, the profile for a role
-
A section on feedback that addressed the definition of the role
-
A section on “takeaways” regarding the framework as a whole
-
A section on proposed new overarching themes
To analyze the feedback from each stakeholder workshop, selected RDaF team members first reviewed the rapporteur’s notes to familiarize themselves with the discussion. Then these team members viewed the recording of the workshop, read through any written comments provided in the workshop chat, and noted every comment in the appropriate section of the template. After the first draft of the template notes was completed, the team members viewed the recording a second time, added any missing comments, and converted each comment and suggestion concerning a topic or subtopic into a potential change for review. Finally, the entire RDaF team considered each potential change and generated an updated interim V1.5 of the framework foundation.
2.2.2 Input for Profile Development
After updating the framework foundation based on the stakeholder feedback, the next step involved the generation of a sample profile for each role addressed by a workshop. As the feedback from the stakeholder workshops concerning profiles was limited and varied in form and specificity, more data were needed to develop these profiles.
The updated topics and subtopics were used to develop blank checklists of topics and subtopics for the lifecycle stages discussed at each of the 15 stakeholder workshops. The appropriate spreadsheet was sent to the participants of a given workshop with instructions to mark those topics and subtopics that were most relevant to the role addressed at that workshop. About 60 participants submitted out a spreadsheet with their responses for the workshop they attended.
The responses were analyzed for similarities and several roles were modified. For example, professors and researchers were grouped together to form one role as professors are typically involved in their groups’ research. After consideration of the participants’ responses, the RDaF team selected eight common job roles for the generation of sample profiles. These roles are AI expert, curator, budget/cost expert, data and IT expert, provider of data tools, publisher, research organization leader, and researcher.
For each sample profile, the RDaF team first calculated the percentage of responses that labeled a subtopic as relevant. When 50% or more of the respondents considered a subtopic to be relevant, it was presumptively deemed relevant for the sample profile. Next, the team considered all comments received with the profile responses as well as all the notes from the Stakeholder Workshop to further flesh out the sample profile. Lastly, the RDaF team consulted with experts in these roles to finalize the profiles.
2.2.3 Request for Information on Interim Version 1.5
Interim V1.5 of the RDaF was published in May 2023 [4]. This publication included the entire list of topics and subtopics for the six lifecycle stages, definitions, informative references for most of the subtopics, 14 overarching themes, and eight sample profiles.
The RDaF team developed a Request for Information (RFI) that was posted in the Federal Register on June 6, 2023, to communicate updates to the RDaF and receive additional feedback on V1.5. The public had 30 days after release of the RFI to comment on any aspect of the RDaF. The RDaF team reviewed and distilled the comments into almost 70 possible action items which were considered individually within the context of the intent of the framework. All comments received were considered in generating V2.0 of the framework.
2.3 Development of an Interactive Web Application
A web application has been developed and released that presents an interface to the RDaF components—lifecycle stages, topics, subtopics, definitions, informative references, overarching themes, and sample profiles—and thus replicates this RDaF V2.0 document in an interactive environment. In addition to providing an easy means of navigating through the various components and the relationships among them, the web application has new functionality such as the capability to link subtopics to their corresponding informative references and to direct a user to the original source of any reference.
The web application runs on a variety of platforms including Windows, MacOS, and Linux. Development of the software—database design, Entity Framework Core, web application framework, search strategies, and user interface—is the subject of a separate publication in preparation.
3 Framework Foundation – Lifecycle Stages, Topics, and Subtopics
The foundation of the RDaF consists of lifecycle stages, topics, and subtopics selected by the RDaF team using a vast amount of stakeholder input as described in Section 2. The RDaF research data lifecycle graphic depicted in Fig. 2 is cyclical rather than linear and has six stages defined below. Each stage is interconnected to all other stages, i.e., a stage can lead into any other stage. An organization or individual may initially approach the lifecycle from any stage and subsequently address any other stage. It is likely that an organization or individual will be involved in all lifecycle stages simultaneously, though with different levels of intensity or capacity.
Envision – This lifecycle stage encompasses a review of the overall strategies and drivers of an organization’s research data program. In this lifecycle stage, choices and decisions are made that together chart a high-level course of action to achieve desired organizational goals, including how the research data program is incorporated into an organization’s data governance strategy.
Plan – This lifecycle stage encompasses the activities associated with preparing for data acquisition, selection of data formats and storage solutions, and anticipation of data sharing and dissemination strategies and policies, including how a research data program is incorporated into an organization’s data management plan.
Generate/Acquire – This lifecycle stage covers the generation of raw research data, both experimentally and computationally, within an organization or by an individual, and the collection or acquisition of research data produced outside of an organization.
Process/Analyze – This lifecycle stage concerns the actions performed on generated or externally acquired research data to yield processed research data, typically using software, from which observations and conclusions can be made.
Share/Use/Reuse – This lifecycle stage outlines how raw and processed research data are disseminated, used, and reused within an organization or by an individual and any constraints or encouragements to use/reuse such data. This stage also includes the dissemination, use, and reuse of raw and processed research data outside an organization.
Preserve/Discard – This lifecycle stage delineates the end-of-use and end-of-life provisions for research data by an organization or individual and includes records management, archiving, and safe disposal.
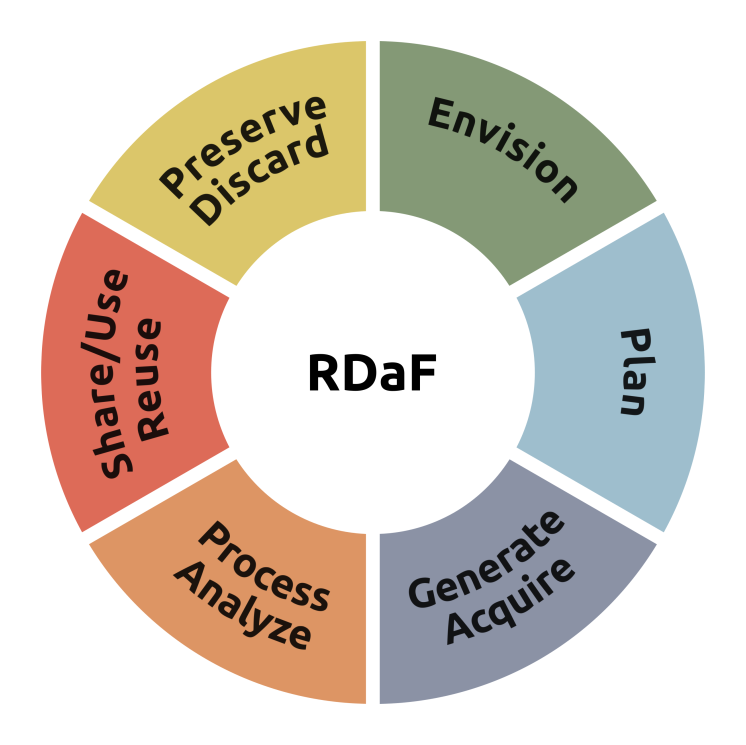
Fig. 2 — Research data framework lifecycle stages
Tables 1-6 presented below each cover one research data lifecycle stage and its associated topics and subtopics. The goal of the framework is to be comprehensive while remaining flexible. An organization or individual may find that not every topic and subtopic in a lifecycle stage is relevant to their work. The selection of subtopics to generate a profile for a job or function will be described in Section 5.
Many lexicons are used in the research data management space. Though the RDaF does not intend to introduce an entirely new vocabulary, it is important to be precise with the use of key terms. For each topic and subtopic, the RDaF provides definitions to assist users in understanding what tasks and responsibilities are associated with that topic or subtopic. To derive these definitions, the RDaF team performed a search of common data lexicons such as CODATA’s Research Data Management Terminology and Techopedia [5, 6]. Additionally, the team searched more broadly for common and research data management-specific definitions, including ones for the informative references that provide guidance in the implementation of the RDaF. Some definitions are general or commonly understood and as such have no references. The definitions were checked for consistency with stakeholder feedback. Individual researchers and organizations should keep in mind that these definitions are not prescriptive and consider their own context when determining whether the definitions provided are appropriate.
Table 1. Envision lifecycle stage
|
Envision: Topic |
Subtopic |
Definition |
|
Data Governance – Strategic/Qualitative |
Identification of goals and roles |
An exercise to define the objectives of, and responsible individuals for, various aspects of research data management (RDM). |
|
The policies, procedures, and processes pertaining to authority, control, and shared decision-making (planning, monitoring, and enforcement) over the management of data assets. [9, 10] |
Vision and/or policy |
Vision is an aspirational state an
organization wishes to achieve with respect to RDM. |
|
Data management organization |
An RDM infrastructure (RDMI) of human and capital resources that supports data-related activities, e.g., policies, planning, and sharing, as well as practices and projects, e.g., data acquisition, control, and protection. Groups or individuals managing data across multiple platforms will need to ensure alignment and interoperability across the infrastructure. [11] |
|
|
Organizational values, including DEIA |
A set of core beliefs that function as guides to what is seen as good and important in an organization and the guiding principles that provide an organization with purpose and direction. Values ideally include diversity, equity, and inclusion, and accessibility. [12, 13] |
|
|
Data management value proposition |
A clear statement that indicates exactly what benefits an organization will derive from an RDM program. [14] |
|
|
Data needs assessment |
An evaluation of the requirements of an organization regarding research data, e.g., storage and technical support for data-related activities. |
|
|
Purpose and value of data |
A clear statement of the need for, use of, and benefit derived from, research data. |
|
|
Organization intent regarding FAIR data |
The extent to which an organization supports the internal adoption and use of the FAIR data principles. |
|
|
End-use support |
Components of the RDMI within an organization that enable data to be prepared and processed for its ultimate application, including reuse. |
|
|
Stewardship |
The application of rigorous analyses and oversight to ensure that data assets meet the needs of users. [15] |
|
|
Data Governance – Legal and Regulatory Compliance |
Privacy |
The practice of protecting and properly handling sensitive data, including personal, proprietary, and confidential data. [16] |
|
The policies, procedures, and processes to manage and monitor an organization regulatory and legal responsibilities and risks pertaining to data. [10] |
Ethics |
Moral principles pertaining to data practices, e.g., analysis and dissemination, that have the potential to adversely impact people and society. For example, principles that promote minimizing bias and maintaining the privacy of personal data. See also the Global Data Ethics Project. [17–19] |
|
Safety and security assurance |
The practice of protecting data assets from unauthorized access, theft, or corruption throughout their lifecycles. [20] |
|
|
Inventory |
A function that provides organizational capabilities for archiving data management such that data products can be grouped, searched, and identified for retrieval, statistics and reorganization. Also, a list of available items stored and/or controlled in a storage warehouse system. [15] |
|
|
Risk assessment |
A systematic process for the identification and evaluation of potential threats to, and vulnerabilities of, an organization’s data assets, e.g., unauthorized access to sensitive data. [22] |
|
|
Risk mitigation and management |
A process for the development and implementation of appropriate strategies to control, reduce, or eliminate potential threats to, and vulnerabilities of, an organization’s data assets as identified by a risk assessment. [23] |
|
|
Sharing/licensing |
Data sharing
agreement: a formal contract that details what data are being shared
and the appropriate use for the data. |
|
|
Social license for use and reuse |
An unwritten agreement whereby a group of public stakeholders accept that certain datasets may be applied for purposes other than those for which the data were originally intended, e.g., healthcare data. [28] |
|
|
Jurisdiction for sharing and reuse |
Legal requirements as set by an authoritative entity (e.g., local and national regions) concerning the dissemination of data by an organization and subsequent use of the data by other organizations. [29] |
|
|
Data Culture and Reward Structure |
Roles and responsibilities |
The job functions and obligations that enable the establishment of a desired data culture and reward structure. |
|
The collective beliefs and behaviors of the people in anorganization concerning the value and management of research data. Practices designed to recognize the advantages and accomplishments of sharing data.[30] |
Recognition of data management |
Processes and practices that provide acknowledgement and rewards for good RDM at all levels in an organization. |
|
Value of data workers |
Recognition of the benefits that staff performing data-centric jobs or functions provide to an organization. |
|
|
Promotion and tenure |
Career advancements that are linked to good research processes, practices, and outcomes. |
|
|
Integrity of research and data |
For
research: The condition resulting from adherence to professional
values and practices when conducting, reporting, applying, and
disseminating results of the work. [31] |
|
|
FAIR data principles |
Guidelines that allow digital objects (e.g., data, algorithms, and workflows) to be Findable, Accessible, Interoperable, and Reusable. [33] |
|
|
Maintenance of FAIR data |
Ongoing infrastructural support to sustain FAIR data principles and practices. |
|
|
Incentives and impact for sharing and reuse |
Staff recognition and rewards for widespread dissemination and application of research data and the beneficial effects of such dissemination. |
|
|
Disincentives for sharing and reuse |
Barriers that limit dissemination of data, e.g., misinterpretation and misuse of data by others, lack of recognition, and the effort required for sharing. |
|
|
CARE and ethics |
The CARE
(Collective benefit, Authority to control, Responsibility, and
Ethics) Principles for Indigenous Data Governance are people and
purpose-oriented, reflecting the crucial role of data in advancing
Indigenous innovation and self-determination. (These principles
complement the existing FAIR principles for indigenous data
governance.) |
|
|
Education and Workforce Development |
Workforce |
A catalog of an organization’s capabilities in essential data processes. |
|
Training to provide staff with the necessary skills and expertise for data-related activities and RDM. Includes leadership support and formal and informal training. |
Workforce preparedness in new and advanced technologies |
Assessment of needs for, and provision of, training in the skills and expertise of an organization’s staff pertinent to novel and leading-edge areas of research, e.g., AI. |
|
Data management training |
In-classroom, on-line, and/or hands-on instruction for staff to attain the skills and expertise required to manage data across a lifecycle. |
|
|
HR’s supporting role in workforce development and training |
Involvement of an organization’s Human Resources (HR) department in establishing and implementing instructional courses for staff to expand their skill sets and expertise in research data programs and RDM. |
|
|
Promotional paths and career development |
Documented approaches for recruitment, advancement, and retention of staff in data-centric jobs in an organization and expansion of data-related skills and expertise for all technical jobs. |
|
|
Resources—Allocation and Sustainability |
Sources of funding |
Entities that provide financial support for research data programs and RDM infrastructure (e.g., capital and human resources). |
|
The distribution and longevity of funding to attain and maintain robust research data programs and RDM infrastructure. |
Long-term funding |
Sustained financial support for research data activities and RDM infrastructure. |
|
Staffing |
Provision of sufficient resources to support RDM staff and researchers engaged in RDM activities. |
|
|
Community Engagement |
Stakeholder communities |
Individuals, groups, and organizations that have an interest or stake in RDM or research data in general, and in particular domains. [35] |
|
Outreach and interactions among organizations or individuals with shared goals or interests concerning research data activities or RDM. |
Modes of communication |
Ways by which information about research data and data management are shared and discussed. |
|
Partners/partnerships |
Partner: Two
or more organizations or individuals that share responsibility and
control of ideas, processes, and outcomes of research data
activities. |
|
|
Engagement across knowledge domains and sectors |
Interactions among groups or individuals having expertise in different specific, specialized disciplines or fields, or expertise in different technology areas. [37] |
|
|
Inclusivity in interactions |
The practice of including all types of people or ideas and treating them all fairly and equally. [38] |
|
|
Data services and the beneficiaries |
Solutions for data tasks (e.g., data transfer, storage, and analytics) and the organizations or individuals deriving value from such solutions. [39] |
|
Plan: Topic |
Subtopic |
Definition |
|
Chain of Custody |
Roles and responsibilities |
The job functions and obligations for tracking data assets. |
|
A complete, fully documented step-by-step history of a data asset in an organization, i.e., who has possession of a data asset, at what time, and for what purpose, at all times throughout the lifecycle of the data asset. [40] |
Implementation authority |
Person empowered to grant access to data assets, e.g., a Chief Data Officer. |
|
Centralized inventory of services, groups, and resources |
An organization-wide catalog of items supporting data-related activities at various levels of an organization, including capital (e.g., HPC), virtual (e.g., domain repositories), and human (e.g., Data Steward and AI interest group) components. |
|
|
Provenance |
The historical, attributed, and documented record of a data asset that contains details on its origin—where, when, how, and by whom it was generated/acquired/processed—and on all alterations to the data asset. [15] |
|
|
Financial Aspects of Planning |
Funding models for provisioning resources |
Approaches for providing financial support for data-related activities and infrastructure, including direct, (e.g., grants, contracts, and institutional), overhead, or mixed. [42] |
|
Factors to consider in estimating or assessing the costs associated with all research data and RDM activities over the data lifecycle. |
Funding sources |
Entities that provide financial support for research data activities and infrastructure (e.g., capital and human resources). |
|
Decision-making tools to assess costs |
Methods to determine the financial requirements of various data activities and infrastructure, e.g., cost-benefit analysis, market analysis, and decision trees. |
|
|
Cost-benefit analysis |
A systematic approach to estimating the strengths and weaknesses of alternative actions to determine options which provide the best approach to achieving benefits while preserving savings. [43] |
|
|
Cost breakdown by lifecycle stage |
Identification of funds required for each data activity in a project (e.g., hardware, software, and staffing for data generation), or for an RDM infrastructure (e.g., centralized data services). |
|
|
Downstream lifecycle costs |
Funds required after establishment of an RDM infrastructure (e.g., technology refresh and maintenance) or for later-stage data activities (e.g., long-term preservation). |
|
|
Staffing and training |
Costs incurred in assuring that new staff with appropriate skills and expertise are hired for specific data activities and that existing staff attain new and advanced skills through instructional courses. |
|
|
Data Management Planning |
Written data management plans (DMPs) |
Also known as Data Management and Sharing Plans (DMSPs), these documents provide information on the following topics: Administrative Data, Data Collection, Documentation and Metadata, Ethics and Legal Compliance, Storage and Backup, Selection and Preservation, Data Sharing, and Responsibilities and Resources. DMPs are living documents that should be updated as projects change and mature. [44, 45] |
|
The process of organizing and specifying objectives and activities throughout the research data lifecycle. |
Purpose/intent of research study and context of anticipated data use |
Clear articulation of research objectives in terms of data products that are essential to address specific research and/or technical requirements. |
|
Specification of data entities and actions throughout the lifecycle |
Detailed descriptions of all information, processes, software, and hardware required from conception to completion of a research data project. |
|
|
Machine-readable DMPs |
Data management plan documents in a form that can be used and understood by a computer. DMPs may also be machine-actionable or in a form such that computers can be programmed against the structure. [46] |
|
|
Linkage of DMPs to administrative records |
Interconnection of a research data management plan to operational data, e.g., agreements, transactions. |
|
|
Data organization to facilitate future access |
The practice of categorizing, classifying, and storing data with sufficient detail and specificity such that the data are readily discoverable and usable by others. Examples include databases and repositories. [47] |
|
|
Data management expertise and training |
In-class, on-line, and/or hands-on instruction for staff to attain the skills and knowledge required to manage data in a research study. |
|
|
Data Object |
Quantitative and qualitative |
Quantitative data are numerical data, e.g., measurements and some controlled observations and questionnaires. Qualitative data are defined as non-numerical data, e.g., text, videos, photographs, or audio recordings. [48] |
|
An entity that, together with associated metadata, is produced or used in a research study. [15, pg 13] |
Measurement |
A quantity in various formats, including numerical, visual, and auditory. |
|
Observation |
A fact or occurrence often involving measurement with instruments. [49] |
|
|
Survey |
A list of questions aimed at extracting specific data from a particular group of people. [50] |
|
|
Software |
A computer-based application that converts inputs into outputs to support the user in one or more research tasks. [51] |
|
|
Model |
A representation, pattern, or mathematical description that can help scientists replicate a system, process, or research result. [52] |
|
|
Documentation (text) |
Comprehensive information that accompanies a dataset, including all associated metadata, a data dictionary, descriptions of methods, instruments and software used to generate/collect and process the data, and other supporting data (e.g., duplicate sample results, replicate analyses). [53] |
|
|
Specimen (physical sample) |
A tangible object that may observed or tested to determine its properties or characteristics. |
|
|
Presentation |
Material assembled to explain and describe research results or processes to an audience. |
|
|
FAIR |
Organizational support for making data more FAIR |
Institutional resources to improve the extent of "FAIRness" of data. (FAIRness is used herein to denote a continuum state ranging from no FAIR aspects to fully FAIR.) |
|
Findability, Accessibility, Interoperability, Reusability: a set of guiding principles to support the reusability of data that are beneficial to all scholarly digital research objects. [33,54] |
Identification of methods/guidelines vis-à-vis FAIR principles |
An exercise to locate techniques and recommended procedures related to FAIRness. |
|
Data/Metadata Considerations |
Criteria for selection of data/metadata |
Requirements and needs by which decisions are made regarding what information to generate, collect, and document in a research study. |
|
Factors to take into account prior to conducting a research study. |
Nature of data/metadata required |
Specification of the requisite types and characteristics of selected information. |
|
Intended extent of FAIRness |
The degree to which data and metadata are meant to comply with the FAIR data principles. |
|
|
Methods to capture and store data/metadata |
Techniques or means by which data/metadata are collected, recorded, and preserved. |
|
|
Metadata schema |
The overall structure of data about the data. Two examples of general-purpose metadata schema are Dublin Core and MODS (Metadata Object Description Schema). [55, 56] |
|
|
Data Architecture |
Design |
A set of principles that are formulated from specific strategies, rules, models, and guidelines for the management and flow of a dataset throughout its lifecycle. |
|
The fundamental structure of an organization's research data management (RDM) system embodied in its components, their relationships to each other and to the environment, and the principles guiding its design and evolution. Includes, for example, system interfaces, authentication mechanisms, data brokers, and monitoring platforms [60, 61] |
Processing operations |
Methodology for translating raw data into useable information. Specific methods include, e.g., data preparation, validation, sorting, aggregation, analysis, and reporting. |
|
Workflow |
The process of managing data in a structured manner. It involves collecting, organizing, and processing data so that they can be used for various purposes. [57] |
|
|
Model |
A detailed description or scaled representation of the relationships and data flow between different components of an RDM system, typically in the form of a diagram or flowchart. [58] |
|
|
LIMS |
A laboratory information management system (LIMS) is a software system developed to support laboratory operations (e.g., track specimens and workflows and aggregate datasets). [59] |
|
|
Hosting and storage, cloud storage |
Methods whereby, and locations wherein, data are saved and from which data can be retrieved. |
|
|
Configuration management |
The actions of tracking and controlling changes in the hardware and software components, e.g., updates and version control. [62] |
|
|
Interoperability among different architectures |
The capability to communicate, execute programs, or transfer data among different RDM systems in a useful and meaningful manner that requires the user to have little or no knowledge of the unique characteristics of those systems. [63] |
|
|
Security |
Features of the architecture that protect data from unauthorized access, denial of access, corruption, or theft throughout their entire lifecycles. [20] |
|
|
Existing standards |
Standards relevant to data architecture, including schema (e.g., based on SQL and JSON), format (e.g., JSON and, XML), and APIs (e.g., Google Search for the web). |
|
|
Hardware and Software Infrastructure |
Organizational research needs |
Essential resources required to accomplish the objectives of research projects and RDM (e.g., centralized infrastructure, appropriate training, and support staff). |
|
The physical and non-physical functional components that collectively form a foundation for conducting research and RDM. |
Tools to support data-related processes |
Items, e.g., instruments, methods, utility software, and APIs, that enable research. |
|
Models that connect infrastructure to data processes and workflow |
A detailed description or scaled representation of the relationships between data tasks and movement and the hardware and software components in an RDMI. [58] |
|
|
Interoperability |
The capability to seamlessly communicate, execute programs, or transfer data among various functional components, that requires the user to have little or no knowledge of the unique characteristics of those components. [63] |
|
|
Persistent instrument identifiers |
Globally unique, persistent, and resolvable identifiers of operational scientific instruments enable research data to be persistently associated with such crucial metadata, helping to set data into context. The Research Data Alliance’s Persistent Identification of Instruments Working Group (PIDINST) developed a metadata schema, prototyped implementation of the schema and demonstrated the viability of the proposed solution in practice. [64] |
|
|
Sustainability of data vis-à-vis obsolete infrastructure |
Concerns regarding the ability to reproduce and reuse data if the hardware and software components become outdated or non-functional. |
|
|
Security and privacy considerations |
Security: the degree of protection of data from unauthorized access, denial of access, corruption, or theft provided by the hardware and software. Privacy: the practice of protecting and properly handling sensitive data, including personal, proprietary, and confidential data. [20] |
|
|
Staff expertise and support staff |
Personnel with the appropriate skills and knowledge to maintain and update the hardware and software infrastructure as needed, and personnel to interface with researchers using the infrastructure. |
|
|
Research Data Standards |
Requirements and needs |
Criteria by which decisions are made regarding the type of research standard, i.e., broadly applicable or limited to a particular field of research. |
|
Documents, including codes, specifications, recommended practices, classifications, test methods and guides, that describe how data should be stored or exchanged for the consistent collection and interoperability of that data across different systems, sources, and users. [65, 67] |
Sources of standards/guidelines for data/metadata |
Origins of accepted practices consisting of discrete, reusable components, e.g., data types, identifiers, schemas, and formats. Examples include the Dublin Core Metadata Initiative and Schema.org. [65] |
|
Quality standards |
Guidelines that provide sufficient information to allow all users to readily evaluate the degree of “fitness for purpose” of the data. Key data quality components include completeness, accuracy, integrity, consistency, and timeliness. [15, pg 26, 57] |
|
|
Community-based standards/conventions |
Community-based data and metadata standards are typically long-term endeavors with many different players and types of efforts. Such standards facilitate reuse of data integrative analysis and comparison to other datasets and linkage of data with other research products, such as scholarly material, algorithms and software. [68] |
|
|
Assessment |
Goals/definition of success |
Statement of project objectives; list of accomplishments demonstrating that these objectives were met. |
|
Evaluation of the success of a research project against expectations set before the project has started. |
Metrics for tracking use and impact measures, including reuse |
Quantitative and qualitative indicators of positive influence or outcomes, e.g., number of citations of a dataset and anecdotal evidence of reuse of a dataset. [69] |
|
Communication and Outreach |
Methods to share and reuse data/metadata |
Approaches to disseminate data/metadata and to facilitate reusability of data/metadata, e.g., use of open repositories and maximizing the FAIRness of data. |
|
Engagement and interactions among groups and individuals working in similar research areas. |
Allocation of credit to project team members |
Properly documenting and recognizing each team member's contributions to a project. [70] |
|
Promotion of data to communities of interest |
Modes to communicate the existence and location of datasets to targeted groups, e.g., special-topic data publications and presentations at topical workshops. |
|
|
Cross-institution cooperation |
The process of working with other institutions or organizations on a shared activity (e.g., informal collaborations, formal partnerships, and agreements). |
|
|
Requests for additional data from the research community |
Solicitations of data contributions from partners and stakeholders on areas of mutual interest. |
|
|
Access Control Associated with Data Sensitivity |
Identification of responsible parties for access management |
A determination of those individuals authorized to both prohibit and permit access to sensitive data. |
|
Methods and requirements to limit the individuals or groups permitted to view or use protected data. |
Ease of maintenance and implementation of records |
The extent to which sensitive data can be kept up to date and made accessible to authorized individuals and groups. |
|
Regulatory compliance |
Efforts by organizations to ensure that they are aware of, and take steps to, conform to relevant laws, policies, and regulations concerning sensitive data (e.g., medical records). [71] |
|
|
Sensitive data/PII |
Data that needs to be controlled due to certain risks. Personally Identifiable Information (PII) is any representation of information that permits the identity of an individual to whom the information applies to be reasonably inferred by either direct or indirect means. [72] |
|
|
Limited disclosure, IP |
Restricting release of data to specific legal circumstances and often requiring notification to the data provider. Intellectual Property (IP) refers to certain exclusive rights granted by law to the owner of, e.g., a novel data product. For IP, any agreement must include an assessment of what IP rights subsist in the data, who owns them, what exceptions or limitations apply, and any contractual rights or policies related to IP that should be considered within the data governance framework, including acquired and generated data as well as “background” (i.e., pre-existing) and “foreground” (i.e., from original research) IP. [26, 27, 73] |
|
|
Licensing for reuse |
Legal agreement that allows one party to use another party's data subject to certain conditions. |
Table 3. Generate/Acquire lifecycle stage
|
Generate/Acquire: Topic |
Subtopic |
Definition |
|
Data Types |
Measurement |
A quantity in various formats, including numerical, visual, and auditory. |
|
Classifications or categories of data. [74] |
Text file |
A type of digital, non-executable file that contains letters, numbers, symbols and/or a combination of these without any special formatting (e.g., ASCII, EBCDIC). [75] |
|
Computation, simulation |
Computation: an act, process, or method of computing. Simulation: any research or development project wherein a model of some authentic phenomenon is created to mimic outcomes that happen in the natural world. [76, 77] |
|
|
Source code |
A set of instructions and statements written by a programmer using a computer programming language. This code is later translated into machine language by a compiler. [78] |
|
|
Observation |
A fact or occurrence often involving measurement with instruments. [49] |
|
|
Survey |
A list of questions aimed at extracting specific data from a particular group of people. [50] |
|
|
Transaction |
Data that describe an exchange or transfer of goods, services, or funds. [79] |
|
|
Social media |
Interactive technologies that facilitate the creation and sharing of information (i.e., data) through virtual communities and networks. [80] |
|
|
Data Sources |
In-house generation by researchers |
Data created by researchers within an organization and at a physical location internal to the organization. |
|
Description of circumstances whereby data are produced. Origin of data. |
Remote generation by researchers |
Data created by researchers within an organization through control of an instrument or device at a location other than the organization. |
|
In-field generation by researchers |
Data created by researchers within an organization at a physical location external to the organization, which may be a natural environment. |
|
|
User facility generation by/for researchers |
Data created by researchers or facility staff at a federally sponsored research facility available for external use to advance scientific or technical knowledge. [81] |
|
|
Historical |
Data generated or collected in the past, which may have uncertainties due to, e.g., age and loss of metadata. |
|
|
Human-annotated |
The process of adding metadata or other information in different formats to data by a person such as labels or tags to describe the content or context of images, and labels or tags to classify or extract relevant information from text. Such annotation allows the AI and ML models to categorize the data and approve the execution of relevant tasks. [82] |
|
|
Generated Experimental Data |
Source of objects/subjects |
Origin of items used in an experiment. |
|
Data produced by automation or active intervention by a researcher to induce and measure changes or to create differences when a variable is altered. [83] |
Characteristics of objects/subjects |
Distinct features of items used in an experiment, e.g., appearance and properties. |
|
Conditions of research study |
Description of the external physical environment in which data were collected (e.g., temperature, atmosphere). Such conditions are types of metadata. |
|
|
Specification of instruments and tools |
Identification and documentation of measurement equipment and other items, e.g., software, methods, and materials, used in an experimental research study. Includes descriptions of the technical details and requirements of each item. |
|
|
Parameters for instruments and tools |
Variables or settings on an instrument or tool that are maintained and controlled during an experiment (e.g., laser intensity, gas flow rate, and rate of data collection). |
|
|
Methods, protocols, and calibration |
Techniques and procedures used in the generation of data. |
|
|
Data/metadata capture methods |
Techniques and procedures for collecting and recording information, for both short-term and long-term storage. |
|
|
Provenance and capture methods |
Techniques and procedures for collecting and recording the historical, attributed, and documented record of a data asset that contains details on its origin—where, when, how, and by whom it was generated/acquired/processed—and on all alterations to the data asset. [21, 41] |
|
|
Reproducibility |
The ability to replicate data using identical tools (e.g., documented metadata, code, methods, and instruments) employed previously by the original researchers or by other researchers, without the need for any additional information or communication with the original researchers. [84, 85] |
|
|
Generated Computational Data |
Input data/metadata |
Information of any type that is entered manually or via an automated process into an instrument, computer, or other device. |
|
Data produced by using calculations, models, simulations, or other methods. Can be produced manually or using a computer or other type of system or device. [76, 77] |
Output data/metadata |
Electronic data produced by an instrument, processor, computer, or other device. |
|
Hardware |
The physical components that make up a computer or electronic system and everything else involved that is physically tangible, including monitors, hard drives, memory, and the CPU. [86] |
|
|
Parameters and conditions for computation |
Hardware or software system requirements or configurations that are necessary for a hardware or software application to run smoothly and efficiently, e.g., operating system dependencies, compilers, and memory requirements. [87] |
|
|
Versioning |
The process of numbering different releases of entities, e.g., software, hardware, and documents, for the purposes of tracking and recording changes. This provides the ability to revert to a previous revision, which is critical for data traceability and data re-creation, tracking edits, and correcting errors. [88, 89] |
|
|
Data/metadata capture methods |
Techniques and procedures by which information is collected and recorded. |
|
|
Provenance and capture methods |
Techniques and procedures for collecting and recording the historical, attributed, and documented record of a data asset that contains details on its origin—where, when, how, and by whom it was generated/acquired/processed—and on all alterations to the data asset. [15, pg 24, 31] |
|
|
Verification/validation of output data |
Verification: the process of determining that a computational model accurately represents the underlying mathematical model and its solution. Validation: the process of determining the degree to which a model is an accurate representation of the real world from the perspective of the intended uses of the model. [90] |
|
|
Qualitative Data |
Nature of objects/subjects |
Types and characteristics of entities which are being studied. |
|
Data that are descriptive and concern phenomena which can be observed but not measured. |
Methods and protocols |
Techniques, standard operating procedures, sets of rules, and guidelines. |
|
Metadata |
Data about data, i.e., data that define and describe the characteristics of other data. Using a survey as an example, metadata include the questions in, and location of, the survey. [91] |
|
|
Paradata |
Data about the process by which data were collected. Formalized data on methodologies, processes, and quality associated with the production and assembly of statistical data. Using a survey as an example, paradata include the mode of the survey and responders' response times. Note that paradata are typically associated with social science disciplines; in physical and medical science disciplines, paradata would be included in metadata. [92, 93] |
|
|
Data/metadata/paradata capture methods |
Techniques and procedures for collecting and recording any type of data, either manually or via an automated process using an instrument, computer, or other device. |
|
|
Acquired Data |
From collaborators |
Originating from other individuals or other organizations partnering with researchers in an organization. |
|
Data used in a research study that were not generated by the researchers conducting the study. |
From repositories |
Originating from a destination designated for data storage. Operations of a repository include preservation, management, and provision of access for digital materials that may have different types and formats. [94] |
|
From the literature |
Originating from a publication. |
|
|
Aggregated datasets from multiple sources |
Data compiled from disparate studies that are organized, and summarized so that conclusions can be drawn, and decisions made, from such data-rich collections. |
|
|
Provenance |
The historical, attributed, and documented record of a data asset that contains details on its origin—where, when, how, and by whom it was generated/acquired/processed—and on all alterations to the data asset. [21, 41] |
|
|
Restrictions, fees, and usage agreements |
Mechanisms that may limit the use of acquired data. |
|
|
Critically Evaluated (CE) Data |
Infrastructure to assure the greatest data integrity |
A foundation composed of practices, processes, and procedures designed to produce data that are clean, traceable, and fit for purpose. NIST and KRISS are two institutions that produce critically evaluated data named Standard Reference Data. [95] |
|
Numerical data that have undergone rigorous review and critique such that the integrity, reasonableness, and usability are optimized. [96] |
Single researcher dataset |
A group of data that originates from an individual researcher. |
|
Aggregation of data evaluated by experts |
The process by which data from disparate sources are compiled, reviewed, critiqued, and summarized by subject matter experts. |
|
|
Reproducibility and uncertainty quantification |
Reproducibility: The ability to replicate data using identical tools (e.g., documented metadata, code, methods, and instruments) employed previously by the original researchers or by other researchers without the need for any additional information or communication with the original researchers. Uncertainty quantification: Assignment of a numerical value to a non-negative parameter characterizing the dispersion of the quantity values being attributed to a measurand. Critically evaluated data have great reproducibility and small uncertainty. [84, 85] |
|
|
Intellectual property rights |
Legally enforceable claims for owners of original ideas, inventions, and creative expressions. For intellectual property (IP), any agreement must include an assessment of what IP rights subsist in the data, who owns them, what exceptions or limitations apply, and any contractual rights or policies related to IP that should be considered within the data governance framework, including acquired and generated data as well as “background” (i.e., pre-existing) and “foreground” (i.e., from original research) IP. [26, 27, 97] |
|
|
FAIR Principles |
Data born FAIR |
Data objects that comply with the FAIR principles when first generated or produced. |
|
Findability, Accessibility, Interoperability, Reusability: four concise and measurable guidelines designed and broadly endorsed to support the reusability of data. Standards may be created that align with the FAIR principles but are not recognized standards. |
Data made FAIR |
Data objects that are transformed or changed in some manner so that they comply with the FAIR principles. |
|
FAIR digital objects |
Standardized, autonomous, and persistent entities which contain the information needed about different kinds of digital objects (e.g., data, metadata, documents, software, and semantic assertions), to enable both humans and machines to Find, Access, Interoperate, and Reuse (FAIR) these digital objects in highly efficient and cost-effective ways. [98] |
|
|
FAIR on a continuous scale |
Recognition that there is a degree of FAIRness that ranges from fully FAIR to not FAIR, that may be represented on a numerical scale. |
|
|
Guidelines/methodologies for each aspect: F, A, I, R |
Means, e.g., standards, best practices, protocols, and software, by which the findability, accessibility, interoperability, and reusability of data may be improved. |
|
|
Tools to capture FAIR provenance |
Techniques and procedures for collecting and recording the collective information on the FAIRness of a data asset, from its origin to the present. |
|
|
FAIR instruments and tools |
Equipment, devices, methods, standards, and other tools that enable the findability, accessibility, interoperability, and reusability of data (e.g., SmartAPI). [99] |
|
|
Not FAIR data |
Data that are not findable, accessible, interoperable, and reusable to any degree for various reasons, e.g., obtained using old or obsolete instruments or software. |
|
|
Community-Based Standards |
General vs. domain-specific |
Broadly applicable as opposed to limited to a particular field or area. |
|
Documents, including codes, specifications, recommended practices, classifications, test methods, and guides, that are developed by a group with common interests. |
Standards development organizations vs. community consensus |
Formal, recognized, standards bodies (e.g., ISO and ASTM International), as opposed to informal, self-assembled groups of individuals or institutions with shared interests (e.g., professional societies). |
|
Data format and file structure |
Data format: the organization of data according to preset specifications. File structure: The manner by which data and code are organized within a file with the goal of reusability. In the context of standards, the syntax, encoding, and file format or media type for storing or transmitting data (e.g., CSV and JSON). [65, 100–102] |
|
|
Metadata format and file structure |
Metadata
format: the organization of information metadata according to preset
specifications. |
|
|
Vocabulary and ontology |
Vocabulary: a compendium of standardized terms with consistent semantic definitions. Ontology: a description of data structure (e.g., classes, properties, and relationships in a domain of knowledge. [65, 105] |
|
|
Interoperability |
The capability to seamlessly communicate, execute programs, or transfer data among various functional components that requires the user to have little or no knowledge of the unique characteristics of those components. Interoperability standards enable the operational processes underlying exchange and sharing of information between different systems to ensure all digital research outputs are Findable, Accessible, Interoperable and Reusable, according to the FAIR principles. [63, 106] |
|
|
Acquisition Software
|
Open source vs. proprietary |
Programs freely distributed with the source code that researchers can modify and subsequently redistribute modified versions thereof vs. programs that are copyrighted and bear limits against use, distribution and modification that are imposed by their publisher, vendor, or developer. Such programs remain the property of their owner/creator and are used by end-users/organizations under predefined conditions. [107, 108] |
|
LIMS |
A laboratory information management system (LIMS) is a software system developed to support laboratory operations, e.g., track specimens and workflows, and collect, annotate, and aggregate datasets). [59] |
|
|
Instrument control |
Software for configuring the operating parameters of an instrument. |
|
|
Electronic laboratory notebook |
A software tool that digitally replicates paper laboratory notebooks traditionally used in the sciences to record information on observational, experimental, and computational studies. [109] |
|
|
Audio and video recording |
A digital record used to store and preserve the audible and/or visual components of an event. |
Table 4. Process/Analyze lifecycle stage
|
Process/Analyze: Topic |
Subtopic |
Definition |
|
Types of Processed Data |
Tables, spreadsheets |
Tables: numerical and textual information arranged in rows and columns. Spreadsheets: computer programs that can capture, display and manipulate data arranged in rows and columns. |
|
Classifications or categories of data. [74] |
Charts, graphs |
Visual representations of datasets, e.g., diagrams, pictures, and graphs. Graphical charts show mathematical relationships between varied groups of data. [110] |
|
Maps, vectors, images |
Representations of the relationships between variables, i.e., quantities, phenomena, or entities. Maps: diagrammatic depictions of the association of two or three variables. Vectors: linear depictions of two independent variables; Images: visual representations of an object in two or three dimensions. |
|
|
Instrument outputs |
Raw electronic data generated by a piece of equipment, device, or other tool before any human action on the data and before any processing of the data. [111] |
|
|
Dynamic data |
Data which are changing frequently and at asynchronous moments. Data that may change after they are recorded and have to be continually updated. [112, 113] |
|
|
Datasets from models and simulations |
Organized collections of data generated by models (I.e., representations, patterns, or mathematical descriptions that can help scientists replicate a system, process, or research result) and simulations (i.e., creation of a model of some authentic phenomenon to mimic outcomes that happen in the natural world.) [52, 76, 114, 115] |
|
|
Structured data |
Data whose elements have been organized (e.g., hierarchical) into a consistent format and data structure within a defined data model such that the elements can be easily addressed, organized, and accessed in various combinations to make better use of the information (e.g., a relational database). [116] |
|
|
Preparation and Pre-Processing Methods |
Data cleaning |
The process of detecting and correcting corrupt or inaccurate records from a dataset. This process involves identifying, replacing, modifying, or deleting incomplete, incorrect, inaccurate, inconsistent, irrelevant, and improperly formatted data. [117] |
|
Techniques by which raw data are transformed into complete datasets with consistent formatting such that data analysis can subsequently be performed. [119] |
De-identification, anonymization |
A process by which personal data are irreversibly altered in such a way that a data subject can no longer be identified directly or indirectly, either by the data controller alone or in collaboration with any other party. [118] |
|
Amputation and imputation |
Amputation: a process whereby some valid data points are selectively deleted from a complete dataset. Imputation: a process used to determine and assign replacement values for missing, invalid, or inconsistent data. [120, 121] |
|
|
Aggregation |
A process
used to combine datasets, typically taken collectively or in the
form of a summary. Integration of data by aggregation requires data
interoperability, |
|
|
Validation and verification |
Validation: the process of determining the degree to which a model is an accurate representation of the real world from the perspective of the intended uses of the model. Verification: the process of determining that a computational model accurately represents the underlying mathematical model and its solution. [90, 123] |
|
|
Curation |
The ongoing processing and maintenance of data throughout their lifecycle to ensure long-term accessibility, sharing, and preservation. Data curation is composed of research data management and digital preservation and involves processes such as the addition of metadata to make data more findable and understandable, ingestion of data into a repository, validation of file checksums and file fixity checks, and other tasks for organizing, cleaning, describing, enhancing, storing, and preserving data. [124] |
|
|
Normalization of metadata |
The adjustment of metadata elements into standard formats. [125] |
|
|
Analysis Methods |
Manual |
Collection, organization, and transformation of data by a human without using a machine or any other tool. [126] |
|
Statistical and/or logical techniques that are systematically applied to describe and illustrate, condense and recap, and evaluate and interpret data, with the goal of producing new, meaningful information. [74] |
Exploratory |
Techniques that typically use visual tools to, e.g., determine the main characteristics of datasets, find relationships among datasets or variables that may have been unknown or overlooked, and discern trends or differences among datasets. [126, 127] |
|
Descriptive |
Techniques for answering the question, "What happened?", e.g., identifying trends and relationships using current and historical (past) data. [128] |
|
|
Diagnostic |
Techniques for answering the question, "Why did this happen?", e.g., determining the causes of trends and correlations among datasets or variables. [129] |
|
|
Evaluative |
Techniques for a systematic determination of merit, worth, value, or significance of datasets, e.g., relevance to the project objectives. [130] |
|
|
Predictive |
Techniques for answering the question, "What might happen in the future?", e.g., making assumptions about the future using historical data, either manually or with machine-learning algorithms. [131] |
|
|
Prescriptive |
Techniques for answering the question, "What should we do next?", e.g., informing an optimal course of action, decisions and strategies, often via machine learning. [132] |
|
|
Correlational |
Techniques that provide a statistical measure indicating how strongly two variables are related and whether that relationship is positive (e.g., when one variable increases, the other also increases) or negative (e.g., when one variable increases, the other decreases). [133–135] |
|
|
Statistical |
Techniques whereby data are interpreted to uncover patterns and trends. The five basic statistical techniques are mean, standard deviation, regression, hypothesis testing, and sample size determination. [136, 137] |
|
|
Automated, autonomous |
Techniques that require no human guidance or direct intervention and are based solely on machines, e.g., self-driving vehicles. [138] |
|
|
Modeling |
Visualization |
Techniques for the representation of data (e.g., graphs, images, and diagrams). Transformation of numerical data into a visual or pictorial context in order to assist users in better understanding what the data mean. [122, 139] |
|
A class of computational methods whereby a representation, pattern, or mathematical description is used to replicate a system, process, or research result. [52] |
ML, AI |
Machine learning (ML) is a methodology that uses statistics and mathematical models to detect patterns in historical data and learning algorithms to make predictions about new data. Artificial intelligence (AI) is a field of study in which computerized systems can learn, solve problems, and autonomously achieve goals under varying (and sometimes uncertain) conditions. ML is a subset of AI strategies. [140, 141] |
|
Iterative model fitting |
A technique whereby the parameters of a model are adjusted in repeated cycles to improve accuracy of the computation. [142] |
|
|
Integrated development environment |
An application that facilitates application development, typically via a graphical user interface (GUI)-based workbench designed to build software applications in combination with all the required tools, e.g., Jupyter and Rstudio. Common features include, e.g., debugging, version control, and data structure browsing. [143] |
|
|
Metadata |
Types of metadata |
The three main categories or classifications of metadata are descriptive, structural, and administrative. [144] |
|
Data about data, i.e., data that define and describe the characteristics of other data. [91] |
Responsible parties |
Individuals whose duties or job functions include the management of metadata, e.g., data owner or metadata steward. [145] |
|
Specification of metadata standards |
Identification and description of those metadata standards categorized as four types: format/technical interchange, structure, content, and value. Standards include recommended practices, classifications, test methods, and guides. [146] |
|
|
Linked data structure |
A deliberate design for the organization of data (structure) wherein information (metadata) is brought together from different sources (linked) to create a new, richer dataset. [147] |
|
|
Persistent identifiers |
A unique and long-lasting reference that allows for continued access to an entity (e.g., document, dataset, instrument, webpage, contributor, and organization). A persistent identifier (PID) may be connected to a set of metadata describing an object rather than to the object itself. Examples of PIDs include DOI, ORCID, ARK, ROR, PIDINST, and Handles. [148, 149] |
|
|
Provenance |
Original authoritative copy |
The single, distinct, absolute version of a dataset from the originating source that is unique, identifiable, and unalterable without detection. It should be sufficient to allow a third party to reproduce the results of the research. [150] |
|
The historical, attributed, and documented record of a data asset that contains details on its origin—where, when, how, and by whom it was generated/acquired/processed—and on all alterations to the data asset. [21, 41] |
Version identification |
For a specific time, definitive determination of a previous dataset made possible by comprehensive information (e.g., raw data, computer code, software, and documentation) on that dataset. Such an ability to revert to a previous version is critical for data traceability, tracking edits, and correcting mistakes. [88] |
|
Derivative product |
Any data, publication, illustration or visualization, or other work that rearranges, presents, or otherwise makes use of an existing dataset. [151] |
|
|
Aggregation |
A process used to combine datasets, typically resulting in a collection or summary. [122] |
|
|
Subset |
A portion of a dataset that is referentially intact. [152] |
|
|
Timestamp |
Temporal information regarding an event that is recorded by a computer and then stored as a log or metadata. [153] |
|
|
CRediT taxonomy |
Contributor Roles Taxonomy (CRediT) consists of a high-level taxonomy, including 14 roles, that can be used to represent the roles typically played by contributors to research outputs. [154] |
|
|
Software |
Commercial vs. custom |
Commercial software is any software or program designed and developed for licensing or sale to end-users or for serving a commercial purpose (e.g., off-the-shelf programs and games). Custom software is made for an individual or organization and performs tasks specific to their needs. [155, 156] |
|
A set of instructions, data, or programs used to operate computers and execute specific tasks. [157] |
Open source vs. proprietary |
Open source typically refers to software that is freely distributed with source code that can modified by users and modified versions may be redistributed. Proprietary typically refers to software that is copyrighted and bears limits against use, distribution, and modification that are imposed by its publisher, vendor or developer. The software remains the property of its owner/creator and is used by end-users/organizations under predefined conditions. [107, 108] |
|
Aggregation tools |
Software or programs that enable the combination of datasets. [122] |
|
|
Surveying tools |
Software or programs that aid in the gathering of responses to questions aimed at extracting specific data from a particular group. [50] |
|
|
Statistical tools |
Software or programs used in statistics, i.e., the collection, organization, analysis, interpretation, and presentation of masses of data. [158] |
|
|
Calculation and analysis tools |
Software or programs that produce knowledge from organized data to draw conclusions, highlight useful information, and support decision-making. |
|
|
APIs |
An Application Programming Interface (API) is a set of protocols, routines, functions and/or commands that programmers use to facilitate interactions between distinct software services. [159] |
|
|
Database management tools |
Software or programs that aggregate diverse data into a database or other consistent resource, handle different types of queries, provide security, and perform other functions. [160] |
|
|
Testing and validation tools |
Methods to determine if software or programs perform the function for which they were designed. Software or programs that help ensure that the data sent to connected applications are complete, accurate, secure, and consistent. [161] |
|
|
Documentation |
Written information that describes the software product to the people who develop, deploy and use it, including technical manuals and online material, such as online versions of manuals and help capabilities. The term is sometimes used to refer to source information about the product discussed in design documentation, code comments, white papers and session notes. [162] |
|
|
Reproducibility and uncertainty quantification |
Reproducibility: the ability to replicate data using identical tools (e.g., documented metadata, code, methods, and instruments) employed previously by the original researchers or by other researchers without the need for any additional information or communication with the original researchers. Uncertainty quantification: assignment of a numerical value to a non-negative parameter characterizing the dispersion of the quantity values being attributed to a measurand. [84, 85] |
|
|
Versioning and maintenance |
The process of numbering different
releases of a |
|
|
Systems resilience and adaptability |
Resilience: the ability of a software system to continue to operate under adverse conditions while maintaining essential operational capabilities, and to recover to an effective operational state in an acceptable time frame. Adaptability: the ability of a software system to tolerate changes in its environment without external intervention. [163, 164] |
|
|
Source code repository |
A storage location for source code (the fundamental component of a computer program) that holds code, makes code available for use, and organizes code in a logical manner. [165, 166] |
|
|
Security and software updates |
Patch, upgrade, or other modification to code that corrects security and/or functionality problems in software. [167] |
|
|
Standards, protocols, and interfaces |
Standards: codes, programs, and associated documentation that describe how data should be stored or exchanged for the consistent collection and interoperability of that data across different systems, sources, and users. Protocols: sets of rules and guidelines. Interfaces: programs that allow a user to interact with computers in person or over a network, or the controls used in a program that allow the user to interact with the program. [168–170] |
|
|
Workflow and Middleware |
LIMS |
A laboratory information management system (LIMS) is a software system developed to support laboratory operation (e.g., track specimens, collect and annotate data and workflows, and aggregate datasets). [59] |
|
Workflow is a depiction of a sequence of connected operations or "steps" that illustrates how data flows through an RDMI. A workflow includes tasks, people involved, tools input, and output for each step. Middleware is a software layer or "glue" situated between applications and operating systems that makes it easier for software developers to perform communication and input/output, so they can focus on the specific purpose of their application. [173–175] |
Laboratory notebook |
A complete, detailed record of the hardware, software, procedures, materials, observations, and relevant thought processes for the research which would enable the work and resulting data to be reproducible. This typically includes an explanation of why the research was done, including any necessary background and references, how the research was performed, the actual data (raw and processed), and where the data are stored. Laboratory notebooks may be paper or electronic. [171] |
|
Tools for automated metadata capture |
Software, hardware, and methods used to collect and record data about data without the need for manual instruction. |
|
|
Anomaly detection and correction tools |
Software, hardware, and methods used to identify items (e.g., operations, observations, events, and results) that do not conform to the expected pattern or result (i.e., anomaly detection) and to restore such items to the expected pattern or result (i.e., anomaly correction). [172] |
|
|
Collaboration tools |
Software and/or software systems that enable communication and sharing of documents, data, analyses, and/or visualizations amongst individuals who are not co-located. |
|
|
Decisions regarding the need for additional data |
Conclusions by researchers that more data are needed to accomplish project goals. |
|
|
Process monitoring and evaluation |
Periodic tracking of the operation and results of a workflow component by systematically gathering and analyzing data to assure that the component is functioning properly. [176] |
|
|
Containerization |
Operating system-level virtualization or application-level virtualization over multiple network resources so that software applications can run in isolated user spaces called containers in any cloud or non-cloud environment, regardless of type or vendor. [177] |
|
|
Reusable workflow component |
A discrete piece of software that can be compiled and packaged as an activity and reused in multiple processes, thereby reducing duplication and enabling sharing of the software with others. [178] |
|
|
Microservices |
An approach to software development in which a large application is built from modular software components (i.e., microservices), each of which does one defined job (e.g., messaging). [179] |
|
|
Distributed workflow across sites |
Computerized information system that is responsible for scheduling and synchronizing the various tasks within the workflow across physical or virtual locations, in accordance with specified task dependencies, and for sending each task to the respective processing entity. [180] |
|
|
Comprehensive report generation |
The production of a single document which includes all the information needed to reproduce a dataset, including, e.g., methods, format standards, and software versions. |
|
|
Hardware |
Compute requirements |
Specifications of the raw processing power of a computer to meet the needs for activities, applications, or workloads. Such power may be characterized as the rate at which operations are performed, e.g., million instructions per second (MIPS). [181, 182] |
|
The physical components that make up a computer or electronic system and everything else involved that is physically tangible such as peripheral devices. [86] |
Storage requirements |
Specifications and needs for devices and components that store data on a long-term basis for later uses and access (e.g., hard disks and network-attached storage devices). In contrast to storage, memory is the short-term location for temporary data storage. [183] |
|
Network requirements |
Network capability is characterized by stability of the signal, throughput (transfer rate of data from a source system to a destination system), and bandwidth (the amount of data that can be transferred per second, in megabits/sec). [184] |
|
|
Accelerator requirements |
Specifications and needs for hardware devices designed to improve the overall performance of the computer. Hardware acceleration is a process where applications offload certain computing tasks to specialized hardware components within the system, enabling greater performance and efficiency. [185, 186] |
Table 5. Share/Use/Reuse lifecycle stage
|
Share/Use/Reuse: Topic |
Subtopic |
Definition |
|
Publishing |
Repository |
A broad term that refers to a designated location where a collection of digital objects is stored in an organized manner such that the collection is findable, searchable, accessible, and reusable. Types of repositories include domain-specific (e.g., discipline or subject matter); generalist (a variety of data types, format, and content); and institutional (i.e., within an organization). [94, 187, 188] |
|
Public disclosure of research datasets and supporting data objects, e.g., associated metadata and software code, in a manner such that the datasets are findable and reusable for others for future research. Published datasets ideally have a persistent identifier. [190] |
Data paper |
A publication that contains datasets, without having to be at the stage of presenting further analysis and conclusions as in a traditional research paper. [189] |
|
Software |
A set of instructions, data, or programs used to operate computers and execute specific tasks. [157] |
|
|
Updates to datasets and new software versions |
To datasets: the functional process of renewing information already contained in a database or stored elsewhere that results in the creation of a new record and may result in storage of existing data as history. To software: patch, upgrade, or other modification to code that corrects functionality problems in software. [167, 191] |
|
|
Data linking |
The process of collating and cross-referencing data from different sources in to create a more valuable and meaningful dataset. [192] |
|
|
Persistent identifier |
A long-lasting and unique reference to a digital object of various types (e.g., document, dataset, and webpage). Persistent identifiers (PIDs) are labels that locate, identify, and share information about digital objects. A PID may be connected to a set of metadata describing an object rather than to the object itself. [148, 149] |
|
|
Metadata |
Data about data, i.e., data that define and describe the characteristics of other data. [91] |
|
|
Integrity of data |
The reliability and trustworthiness of data throughout their lifecycle. The assurance that a digital object is uncorrupted and can only be accessed or modified by those authorized to do so. [74, 193] |
|
|
Quality measures and assessment vis-à-vis fit for purpose |
The degree to which a dataset meets the requirements for its planned usage as determined by an evaluation of quality metrics (e.g., accuracy, completeness, consistency, and timeliness). [194] |
|
|
Peer review of datasets and metadata |
An editorial process prior to publication of a dataset whereby people with a similar degree of expertise and experience as the author review and provide input on the integrity and quality of the dataset. |
|
|
Reference data/digital objects in journal articles |
Journals have different guidelines concerning the publication of digital objects, e.g., raw data and software, that accompany a traditional article. Examples of these guidelines are depositing data in a relevant repository, citing a dataset by its PID, and linking the dataset to the article. [195] |
|
|
Curation |
The ongoing processing and maintenance of data throughout their lifecycle to ensure long-term accessibility, sharing, and preservation. Data curation is composed of research data management and digital preservation and involves processes such as adding metadata to make data more findable and understandable, ingesting data into a repository, validating file checksums and file fixity checks, and other tasks for organizing, cleaning, describing, enhancing, storing, and preserving data. [124] |
|
|
Publisher agreements and policies |
Legal documents that are used to dictate when and how work is published and thereby protect an author’s intellectual property from unauthorized use or reproduction. Open access agreements support individual authors to publish open access data at no cost to themselves. Publisher policies are set by the publisher and include, e.g., copyright and licensing, data privacy, and rights and permissions. [196–198] |
|
|
Incentives for data publishing |
Staff recognition and rewards for widespread dissemination of research data. |
|
|
Mitigation of disincentives for data publishing |
Practices to remove or reduce barriers that limit dissemination of data (e.g., misinterpretation and misuse of data by others, and lack of recognition and effort for sharing). |
|
|
Modes of Dissemination |
Traditional journal article |
A scholarly manuscript submitted to a journal that undergoes a peer review process, an editing and copy-editing process, and finally distribution by publishers able to print and make high-quality scholarly works available to the world. Such manuscripts typically contain analysis and conclusions, but not digital data objects, e.g., raw data and software. [199] |
|
Means by which journal articles, datasets, and other data objects are publicly released. |
Supplementary material |
Peer-reviewed material directly relevant to the conclusions of a manuscript that cannot be included in the printed version for reasons of space or medium (e.g., video clips or sound files). [200] |
|
On request |
Making data available in response to queries typically sent by email. The requester may be required to complete a form, e.g., a data release application agreement. [201] |
|
|
Data landing page |
A standalone web page that a person accesses after clicking on a link from an email, ad, or other digital location. For a dataset, such a web page typically includes a narrative description of the dataset and files or links to files pertaining to the dataset, e.g., the dataset itself and the software used to generate the dataset. [202] |
|
|
Workflow |
A depiction of a sequence of connected operations or steps that illustrates how data flows through a research data management infrastructure. A workflow includes tasks, people involved, tools (e.g., hardware and software), input, and output for each step. [173] |
|
|
Mainstream media |
Traditional means of communication, such as newspapers, television, and radio, that influence large numbers of people. [203] |
|
|
Social media |
A catch-all term for a variety of internet applications that allow users to create content and interact with each other, e.g., Twitter, Instagram, Facebook, and LinkedIn. [204] |
|
|
Attribution
|
Citation metrics |
Measures based on the number of times a single entity (e.g., article and dataset) published by a researcher is mentioned in the published work of other authors. Indicator of the quality or importance of a published entity. Citation data are available from citation databases, discipline-specific databases, and through an emerging range of alternative metrics. [205] |
|
Citation impact |
Quantitative and qualitative tools and methods to measure the impact of an individual's collective work. Quantitative tools, include citation analysis—counting the number of times other authors mention a researcher's published works; the impact factors (IFs) of the journals in which a researcher has published their work (IF is the frequency with which the average article in a journal has been cited in a particular year); and the h-Index for a researcher, which is based on the set of the researcher's most cited papers and the number of citations those papers have received in other authors' publications. Qualitative methods to measure impact include anecdotal evidence. [206, 207] |
|
|
Dataset citation |
The practice of referencing data products used in research (e.g., a DOI or key descriptive information about the data, such as the title, source, and responsible parties). Data citation, like the citation of other evidence and sources, is good research practice and is part of the scholarly ecosystem supporting data reuse. (See the Joint Declaration of Data Citation Principles.) [208–210] |
|
|
Provenance |
The historical, attributed, and documented record of a data asset that contains details on its origin—where, when, how, and by whom it was generated/acquired/processed—and on all alterations to the data asset. [21, 41] |
|
|
Author identity management |
Use of a persistent, unique, digital researcher identifier such as ORCID to, e.g., track the scholarly outputs of a researcher, assign appropriate author credit, and eliminate author name ambiguity. [211] |
|
|
Use of persistent identifiers |
The practice of assigning a unique and long-lasting reference that allows for continued access to a data asset. [148, 149] |
|
|
Versioning |
The process of numbering different releases of a data asset (e.g., a software program and database); the use and management of multiple versions of a document. Version control allows for the ability to revert to a previous revision, which is critical for data traceability, tracking edits, and correcting mistakes. [88, 89, 157] |
|
|
Modes of Sharing |
Standardized formats |
The organization of information according to preset specifications that are agreed upon by formal standards bodies or informal community groups. |
|
Methods whereby datasets and other digital objects are publicly or privately distributed or are accessible to others upon request. |
Interoperability tools |
Methods that provide the capability to seamlessly communicate, execute programs, or transfer data among various functional components in a useful and meaningful manner that requires the user to have little or no knowledge of the unique characteristics of those components. [63] |
|
Discovery platforms |
Software systems that use metadata to identify and recommend sources of data or other digital objects. [212] |
|
|
Catalogs |
Completely organized services that enable any user, e.g., analysts, data scientists, and developers, to discover, explore, and use data assets. [213] |
|
|
Registries of repositories |
Databases containing information about trusted repositories that are provided by the repository managers and are useful for human and machine users, e.g., the Re3data Repository Registry and the NIST Materials Resource Registry. [214–216] |
|
|
Access |
Internal access |
The ability of individuals in an organization to view and retrieve data and other digital objects that were generated, collected, or processed by an individual or group in the same organization. |
|
The ability of a user to view and retrieve data and other digital objects stored within a database or other repository. Users who have data access can store, retrieve, move or manipulate data, which can be retained on a wide range of hard drives and external devices. [217] |
External access |
The ability of individuals in organizations other than the organization that generated, collected, or processed the data and other digital objects to view and retrieve such digital resources. |
|
Programmatic access |
The ability of a user to view and retrieve data made possible by an Application Programming Interface (API), which is a set of protocols, routines, functions and/or commands that programmers use to facilitate interaction between distinct software services. [159] |
|
|
Virtual and physical enclaves |
Secure networks through which confidential data, such as personally identifiable information from census data, can be stored and disseminated. In a virtual data enclave, a researcher can access data from their own computer but cannot download or remove the data from the remote server. Higher security data can be accessed through a physical data enclave wherein a researcher is required to access data from a monitored room where the data are stored on non-networked computers. [218] |
|
|
Access vs. visiting |
Data visiting is an approach whereby sensitive data stays under the control of the owner and consumers (e.g., analysts or machine learning algorithms) are permitted to work with the data on location. With data access, users can store, retrieve, move, or manipulate stored data. [219] |
|
|
Availability statement |
A declaration letting a user know where and how to access data that support the results and analysis of a published study. A declaration may include links to publicly accessible datasets that were analyzed or generated during the study, descriptions of what data are available and/or information on how to access data that are not publicly available. [220] |
|
|
Mitigation of barriers and economic constraints |
Practices that reduce or eliminate programmatic and administrative constraints and transactional costs of accessing data. |
|
|
Legal and Licenses |
Ownership |
The act of having legal rights and complete control over data assets. Ownership defines and provides information about the rightful owner of data assets and the acquisition, use and distribution policy implemented by the data owner. [221] |
|
Juridical and regulatory issues as pertaining to research data. |
Encouragement and support for sharing, use, and reuse |
Incentives and human and infrastructural resources that increase the quantity and quality of data assets for access and dissemination. |
|
Indigenous data rights |
Indigenous data sovereignty (IDS) refers to the right of Indigenous peoples to govern the collection, ownership, and application of data about Indigenous communities, peoples, lands, and resources. IDS encompasses data, information, and knowledge about Indigenous individuals, collectives, entities, lifeways, cultures, lands, and resources. [34] |
|
|
Intellectual property rights/restrictions |
Intellectual property (IP) is something of value (an asset) that is created from an original idea, invention, or creative expression. IP rights are legally enforceable claims for owners of such items, including data products (e.g., software). An IP agreement must include an assessment of what IP rights subsist in the data, who owns them, what exceptions or limitations apply, and any contractual rights or policies related to IP that should be considered within the data governance framework, including acquired and generated data as well as “background” (i.e., pre-existing) and “foreground” (i.e., from original research) IP. [24–27] [222] |
|
|
Usage agreements/terms/licenses and required permissions |
Usage agreements: legally binding contracts between an originator of a digital object and a user of the object that spell out the rights and responsibilities of all involved parties. User licenses: written contracts that give a user permission to work on another party's digital object under a certain set of conditions and typically requires that the user pay a royalty fee. [223, 224] |
|
|
Data sharing and licensing agreements |
Sharing agreements: formal contracts that detail what data are being shared and the appropriate use of the data and include provisions concerning access and dissemination. Licensing agreements: documents that describe what kind of data are being shared with a user and clearly state the purpose and duration of access being provided to the user along with restrictions and security protocols that the user of the data must follow. [24, 25] |
|
|
Service-level agreements |
Contracts between two parties that define and measure the level of service a data provider will deliver to a user The agreements aim to define expectations of the level of service and quality between data providers and users. [225] |
|
|
Terms of service |
Legal agreements between a data service provider and a user that detail the set of rules and regulations a provider attaches to a software service or web-delivered product. [226] |
|
|
Standardized, machine-actionable license documents |
Written contracts in a common, agreed-upon form that can be read, understood, and implemented by a computer. Such contracts give a user permission to use a creator's digital object under a certain set of conditions. |
|
|
Citation requirements |
References to data and other digital objects that are mandated by a data provider, formal agreement, or publishing entity. |
|
|
Levels of Protection |
Unclassified but sensitive information |
A designation of information (data) in the US federal government that is not classified for national security reasons, but that warrants or requires administrative control and protection from public or other unauthorized disclosure for other reasons. Personally Identifiable Information (PII), e.g., an individual's birthdate, address, and phone number and Business Identifiable Information (BII), e.g., trade secrets and financial information, fit this designation. The US government uses the term “controlled unclassified information (CUI).” [72, 227–229] |
|
Classification scheme based on potential harm resulting from unauthorized access, disclosure, loss of privacy, compromised integrity, or violation of external obligations. [230] |
Security classification |
A term typically associated with U.S. federal government national security information. NIST has developed a broader document that addresses security controls, defined as the safeguards or countermeasures employed within a system or an organization to protect the confidentiality, integrity, and availability of the system and its information and to manage information security risk. [231, 232] |
|
Protection of limited data/secure platforms/enclaves |
Limited data: in healthcare, a set of identifiable healthcare information that the HIPAA Privacy Rule permits covered entities to share with certain entities for research purposes if certain conditions are met. Data security platform: aggregates data protection requirements across data types, storage silos, and ecosystems to create an organization-wide data security solution. Secure data enclave: a system that allows data owners to control data access and ensure data security while facilitating approved uses of data by other parties. [233–235] |
|
|
Constraints and restrictions on data use and sharing |
Technical, administrative, or legal limitations on the use and sharing of data. |
|
|
Anonymization |
A process of preserving private or confidential information by deleting or encoding identifiers that link individuals and stored data. [236] |
|
|
Architectures for Application, Use, and Reuse |
Extensibility across communities, including machine-based interactions |
A measure of the ability to expand an RDM architecture to enable interactions with a broad group of stakeholders and types of equipment, achieved by adding new functionality or modifying existing functionality. [237] |
|
The fundamental structure of an organization's research data management (RDM) system embodied in its components, their relationships to each other and to the environment, and the principles guiding its design and evolution. Such a structure should enable a user to capitalize on an organization's data. [60, 61] |
Capture of insights from ML and use of these to improve datasets for future AI applications |
Recording and retaining information obtained via computer systems that use algorithms and statistical models to enable understanding of complex problems and employing such understanding to develop enhanced datasets for new AI solutions. |
|
Capture of data performance characteristics |
Recording and retaining information concerning the quality attributes of a dataset, e.g., validity, accuracy, completeness, relevance, uniformity and consistency. [238] |
|
|
Location of data |
Methods whereby, and systems and devices wherein, data are saved and from which data can be retrieved, e.g., on premises, cloud, temporary cache, and removable media. |
|
|
Migration strategies concerning data loss |
Approaches and practices to eliminate, prevent, or reduce the intentional or unintentional destruction or disappearance of information caused by people, processes, or other means. |
|
|
Economic impact of reuse |
Monetary benefits of using existing data compared to re-generating identical data. |
Table 6. Preserve/Discard lifecycle stage
|
Preserve/Discard: Topic |
Subtopic |
Definition |
|
Criteria for Preservation |
Use |
Instances wherein datasets are utilized for meaningful purposes, e.g., problem-solving and decision-making. |
|
Quantitative and qualitative metrics used to assess the need for long-term retention of data. [239] |
Impact |
Demonstrated, positive outcomes attributed to use of a dataset, e.g., a scientific discovery and a new measurement instrument or product. |
|
Value |
Merit or worth of data in terms of their usefulness and fitness for purpose, e.g., to make sound, fact-based conclusions and decisions. |
|
|
Uniqueness |
The quality of being unlike any other data in terms of, e.g., type and characteristics. [240] |
|
|
Cost |
Financial resources required to store and preserve data. |
|
|
Provenance |
The historical, attributed, and documented record of a data asset that contains details on its origin—where, when, how, and by whom it was generated/acquired/processed—and on all alterations to the data asset. [21, 41] |
|
|
Legal and regulatory |
Requirements via contract, law, regulation, or other agreement to preserve data. |
|
|
Sustainability |
Longevity and support |
The amount of time a dataset is retained in an organization and the resources to maintain this retention. [241] |
|
The capacity to maintain or improve the state and availability of data nd an RDM infrastructure over the long term. [242] |
Funding models |
Approaches to build a reliable funding base that will support an organization's core research data projects and services. [42] |
|
Business models |
Approaches to describe how an organization ensures that its research data projects and services provide value. [243] |
|
|
Storage and Preservation |
Methods to store and preserve data |
Devices and cloud services used to retain data in the short-term and long-term. [244] |
|
Storage is a process whereby digital data are saved for later use and access via, e.g., a device or cloud service. Preservation is a series of managed activities required to ensure continued stability and access to data for as long as necessary. [183 , 248] |
File integrity |
The process of protecting a file from unauthorized changes or environmental hazards, i.e., validation to determine if a file has been altered after its creation, curation, archiving, or other qualifying event. [245, 246] |
|
Ability to do advanced searches |
Capability to narrow a query through, e.g., the use of filters that eliminate irrelevant information and enable the identification of desired content. [247] |
|
|
|
Backup and recovery |
Backup: the process of making copies of data or data files to use in the event the original data or data files are lost or destroyed. Recovery: the process of restoring data that have been lost, accidentally deleted, corrupted, or made inaccessible for any reason. [249, 250] |
|
Moving Data from One Service to Another Across Organizations |
Roles and responsibilities |
The job functions and obligations that enable the movement of data among organizations. |
|
Inter-organizational transit of data. |
Registry maintenance and curation |
The processes of harvesting, organizing, and handling a collection of data-related resources such as repositories, services, and software, to facilitate ease of user searches and retrieval of information. Examples of registries are re3data and the NIST Materials Resource Registry. [215, 216] |
|
Disciplinary archives |
A place to store data from a specific field of study or branch of knowledge that is important but that doesn't need to be accessed or modified frequently (if at all). [74, 251] |
|
|
Retention and Disposition Schedules |
Technical decisions |
Conclusions regarding retention and disposition of research data that are based on scientific considerations such as merit and future potential usefulness of the data, e.g., data archiving. |
|
A timeline and plan of action based on a policy that addresses which data are important to keep for future use or reference, how that data can be searched and accessed at a later date, and which data are no longer needed and can be destroyed. [253] |
Administrative/policy decisions |
Conclusions regarding retention and disposition of research data that are based on logistical or operational considerations, e.g., cost of data archiving. |
|
Deaccessioning/end-of-life |
The formal, documented removal of a data collection or dataset from its location or custody of an archive service. [252] |
|
|
Legal documents |
Schedules for retention and disposition of data set by formal contracts or other agreements. |
|
|
End-of-life special considerations |
Any actions taken before disposition of data that has reached the end of its useful life or will no longer receive support for archiving. An example consideration is adhering to security protocols for sensitive data. |
|
|
Recognition of removed data |
Creation of a special type of landing page (i.e., tombstone page) describing the data that have been removed and providing a full bibliographic citation, a DOI (if one has been assigned), and a statement on unavailability detailing the circumstances that led to removal of the data. [254] |
4 Overarching Themes
The RDaF was refined from the preliminary V1.0 using input from the two opening plenary workshops and the 15 stakeholder workshops. During this refinement process, 14 themes that spanned the various lifecycle stages were identified. Rather than repeat these themes in each stage, they are listed here with a brief explanation of their meaning in the context of research data and research data management (RDM). Following the explanatory narrative, the specific lifecycle stages/topics/subtopics in which each theme appears are shown in tabular form.
In most cases, the overarching themes are supported by explicit references in the framework. In other cases, the themes are implicit. For example, the cost implications and sustainability theme touches on every topic or subtopic, although it is not called out in any lifecycle stage: there is a financial implication to every decision and action that will be considered by those working with research data in any capacity. Note that while these 14 themes emerge from the general definitions of the topics and subtopics, considering the scope of RDM from the perspective of a specific individual or organization, other themes may emerge. Such custom themes can serve as an additional organizing function for job roles, tasks, and other activities represented by the topics and subtopics in the framework.
Separate tables generated for each overarching theme document the topics and subtopics most closely associated to that theme (see Tables 7-20 below). There are also two graphics that provide summary information. Figure 3 is a Sankey diagram that provides a visualization of the relationship between each lifecycle stage and each overarching theme. Figure 4 is a matrix table that gives a high-level overview of the relationships between the overarching themes and the topics for each lifecycle stage. (Some of the overarching theme names in Figs. 3 and 4 have been truncated or abbreviated for visualization purposes.)
Fig. 3 — Sankey diagram of the relationships between lifecycle stages and overarching themes
Fig. 4 — Matrix diagram of topics and overarching themes
4.1 Community Engagement
Community engagement, typically broader for RDM practices and more focused for research data projects, is an intentional set of approaches for both listening to and communicating with stakeholders. Successful research, data management, and data curation come from strong engagement with the community of practice or discipline and the organization in which the research is conducted. Community engagement is present in all the RDaF lifecycle stages, although there is an emphasis on it within the Envision and Plan stages. Engagement with stakeholders early in the research process may result in stronger outcomes and uptake of new research. In the other four lifecycle stages, stakeholder engagement is essential for accomplishing the goals established at the beginning of a research project.
Table 7 lists the topics and subtopics that are most relevant to the overarching theme of community engagement.
Table 7. Community engagement (overarching theme)
|
Lifecycle Stage |
Topic |
Subtopic |
|
Envision |
Data Governance – Strategic/Qualitative |
Identification of goals and roles |
|
Vision and/or policy |
||
|
Data management organization |
||
|
Organizational values, including DEIA |
||
|
Data management value proposition |
||
|
Data needs assessment |
||
|
Organization intent regarding FAIR data |
||
|
End-use support |
||
|
Stewardship |
||
|
Data Governance—Legal and Regulatory Compliance |
Privacy |
|
|
Ethics |
||
|
Data Culture and Reward Structure |
Roles and responsibilities |
|
|
Recognition of data management |
||
|
Value of data workers |
||
|
Promotion and tenure |
||
|
Integrity of research and data |
||
|
FAIR data principles |
||
|
Incentives and impact for sharing and reuse |
||
|
Disincentives for sharing and reuse |
||
|
CARE and ethics |
||
|
Education and Workforce Development |
Workforce skills inventory |
|
|
Workforce preparedness in new and advanced technologies |
||
|
Data management training |
||
|
HR’s supporting role in workforce development and training |
||
|
Promotional paths and career development |
||
|
Resources—Allocation and Sustainability |
Staffing |
|
|
Community Engagement |
Stakeholder communities |
|
|
Partners/partnerships |
||
|
Engagement across knowledge domains and sectors |
||
|
Inclusivity in interactions |
||
|
Data services and the beneficiaries |
||
|
Plan |
Financial Aspects of Planning |
Staffing and training |
|
Data Management Planning |
Purpose/intent of research study and context of anticipated data use |
|
|
Specification of data entities and actions throughout the lifecycle |
||
|
Data organization to facilitate future access |
||
|
Data management expertise and training |
||
|
FAIR |
Organizational support for making data more FAIR |
|
|
Hardware and Software Infrastructure |
Interoperability |
|
|
Security and privacy considerations |
||
|
Research Data Standards |
Sources of standards/guidelines for data/metadata |
|
|
Community-based standards/conventions |
||
|
Communication and Outreach |
Methods to share and reuse data/metadata |
|
|
Allocation of credit to project team members |
||
|
Promotion of data to communities of interest |
||
|
Cross-institution cooperation |
||
|
Requests for additional data from the research community |
||
|
Generate/Acquire |
FAIR Principles |
Guidelines/methodologies for each aspect: F, A, I, R |
|
Community-Based Standards |
General vs. domain-specific |
|
|
Standards development organizations vs. community consensus |
||
|
Vocabulary and ontology |
||
|
Process/Analyze |
Metadata |
Responsible parties |
|
Provenance |
CRediT taxonomy |
|
|
Workflow and Middleware |
Collaboration tools |
|
|
Share/Use/Reuse |
Publishing |
Repository |
|
Peer review of datasets and metadata |
||
|
Curation |
||
|
Publisher agreements and policies |
||
|
Incentives for data publishing |
||
|
Mitigation of disincentives for data publishing |
||
|
Modes of Dissemination |
Data landing page |
|
|
Legal and Licenses |
Indigenous data rights |
|
|
Usage agreements/terms/licenses and required permissions |
||
|
Preserve/Discard |
Criteria for Preservation |
Use |
|
Impact |
||
|
Value |
||
|
Uniqueness |
||
|
Sustainability |
Longevity and support |
|
|
Funding models |
||
|
Moving Data from One Service to Another Across Organizations |
Roles and responsibilities |
|
|
Registry maintenance and curation |
||
|
Disciplinary archives |
||
|
Retention and Disposition Schedules |
End-of-life special considerations |
4.2 Cost Implications and Sustainability
Cost implications and sustainability is a theme that touches every lifecycle stage and most stakeholders in the research ecosystem. From Chief Data Officers and provosts to researchers and grant administrators, cost is a constant focus of all individuals’ work in public and private organizations. Administrators and C-suite officers would typically focus their efforts on the stages of Envision and Plan, while researchers, particularly those with curation duties and service provision, have more impact on the cost implications in the Generate/Acquire, Process/Analyze, Share/Use/Reuse, and Preserve/Discard stages.
Sustainability in research and RDM means sustainable funding, staffing, and preservation models as applied to research data. It is imperative that sustainable plans affecting these three areas are assessed as the areas are developed and maintained to prevent institutions and users from losing access to valuable datasets.
Table 8 lists the topics and subtopics that are most relevant to the overarching theme of cost implications and sustainability.
Table 8. Cost implications and sustainability (overarching theme)
|
Lifecycle Stage |
Topic |
Subtopic |
|
Envision |
Data Governance – Strategic/Qualitative |
Data management organization |
|
Data needs assessment |
||
|
Organization intent regarding FAIR data |
||
|
End-use support |
||
|
Stewardship |
||
|
Data Governance—Legal and Regulatory Compliance |
Risk assessment |
|
|
Risk mitigation and management |
||
|
Data Culture and Reward Structure |
Value of data workers |
|
|
Promotion and tenure |
||
|
FAIR data principles |
||
|
Maintenance of FAIR data |
||
|
Incentives and impact for sharing and reuse |
||
|
Disincentives for sharing and reuse |
||
|
Education and Workforce Development |
Workforce preparedness in new and advanced technologies |
|
|
Data management training |
||
|
Promotional paths and career development |
||
|
Resources—Allocation and Sustainability |
Sources of funding |
|
|
Long-term funding |
||
|
Staffing |
||
|
Community Engagement |
Partners/partnerships |
|
|
Data services and the beneficiaries |
||
|
Planning |
Financial Aspects of Planning |
Funding models for provisioning resources |
|
Funding sources |
||
|
Decision-making tools to assess costs |
||
|
Cost-benefit analysis |
||
|
Cost breakdown by lifecycle stage |
||
|
Downstream lifecycle costs |
||
|
Staffing and training |
||
|
Data Management Planning |
Purpose/intent of research study and context of anticipated data use |
|
|
Data organization to facilitate future access |
||
|
Data management expertise and training |
||
|
Data/Metadata Considerations |
Criteria for selection of data/metadata |
|
|
Data Architecture |
Design |
|
|
Hosting and storage, cloud storage |
||
|
Security |
||
|
Hardware and Software Infrastructure |
Organizational research needs |
|
|
Sustainability of data vis-à-vis obsolete infrastructure |
||
|
Security and privacy considerations |
||
|
Staff expertise and support staff |
||
|
Access Control Associated with Data Sensitivity |
Regulatory compliance |
|
|
Sensitive data/PII |
||
|
Limited disclosure, IP |
||
|
Licensing for reuse |
||
|
Generate/Acquire |
Generated Computational Data |
Hardware |
|
Parameters and conditions for computation |
||
|
Acquired Data |
From collaborators |
|
|
From repositories |
||
|
From the literature |
||
|
Aggregated datasets from multiple sources |
||
|
Restrictions, fees, and usage agreements |
||
|
Acquisition Software |
Open source vs. proprietary |
|
|
LIMS |
||
|
Process/Analyze |
Software |
Commercial vs. custom |
|
Open source vs. proprietary |
||
|
Workflow and Middleware |
LIMS |
|
|
Collaboration tools |
||
|
Hardware |
Compute requirements |
|
|
Storage requirements |
||
|
Network requirements |
||
|
Accelerator requirements |
||
|
Share/Use/Reuse |
Publishing |
Repository |
|
Publisher agreements and policies |
||
|
Legal and Licenses |
Ownership |
|
|
Data sharing and licensing agreements |
||
|
Service-level agreements |
||
|
Architectures for Application, Use, and Reuse |
Economic impact of reuse |
|
|
Preserve/Discard |
Criteria for Preservation |
Cost |
|
Sustainability |
Longevity and support |
|
|
Funding models |
||
|
Business models |
||
|
Storage and Preservation |
Methods to store and preserve data |
4.3 Culture
Culture is the basis for the entirety of a given organization’s success in managing research data and in nearly every other aspect of running a collective enterprise; culture is what gives an institution or organization its character and consistency over time. Cultures are firmly embedded and stem from both informal practices and formal written policies which can make them difficult to change. Culture shapes norms within an organization and creates glide paths towards ingrained values and behaviors as well as resistance to others. Specifically, culture dictates how research data are valued or supported in an institution.
Table 9 lists the topics and subtopics that are most relevant to the overarching theme of culture.
Table 9. Culture (overarching theme)
|
Lifecycle Stage |
Topic |
Subtopic |
|
Envision |
Data Governance – Strategic/Qualitative |
Identification of goals and roles |
|
Vision and/or policy |
||
|
Data management organization |
||
|
Organizational values, including DEIA |
||
|
Data management value proposition |
||
|
Purpose and value of data |
||
|
Organization intent regarding FAIR data |
||
|
Stewardship |
||
|
Data Governance—Legal and Regulatory Compliance |
Ethics |
|
|
Safety and security assurance |
||
|
Risk mitigation and management |
||
|
Sharing/licensing |
||
|
Data Culture and Reward Structure |
Roles and responsibilities |
|
|
Recognition of data management |
||
|
Value of data workers |
||
|
Promotion and tenure |
||
|
Integrity of research and data |
||
|
FAIR data principles |
||
|
Maintenance of FAIR data |
||
|
Incentives and impact for sharing and reuse |
||
|
Disincentives for sharing and reuse |
||
|
CARE and ethics |
||
|
Education and Workforce Development |
Workforce preparedness in new and advanced technologies |
|
|
Data management training |
||
|
HR’s supporting role in workforce development and training |
||
|
Promotional paths and career development |
||
|
Community Engagement |
Stakeholder communities |
|
|
Partners/partnerships |
||
|
Engagement across knowledge domains and sectors |
||
|
Inclusivity in interactions |
||
|
Data services and the beneficiaries |
||
|
Plan |
Chain of Custody |
Roles and responsibilities |
|
Financial Aspects of Planning |
Funding models for provisioning resources |
|
|
FAIR |
Organizational support for making data more FAIR |
|
|
Hardware and Software Infrastructure |
Organizational research needs |
|
|
Interoperability |
||
|
Security and privacy considerations |
||
|
Staff expertise and support staff |
||
|
Research Data Standards |
Requirements and needs |
|
|
Quality standards |
||
|
Community-based standards/conventions |
||
|
Communication and Outreach |
Methods to share and reuse data/metadata |
|
|
Allocation of credit to project team members |
||
|
Promotion of data to communities of interest |
||
|
Cross-institution cooperation |
||
|
Generate/Acquire |
FAIR Principles |
Data born FAIR |
|
Data made FAIR |
||
|
FAIR digital objects |
||
|
FAIR on a continuous scale |
||
|
Guidelines/methodologies for each aspect: F, A, I, R |
||
|
Tools to capture FAIR provenance |
||
|
FAIR instruments and tools |
||
|
Not FAIR data |
||
|
Community-Based Standards |
General vs. domain-specific |
|
|
Standards development organizations vs. community consensus |
||
|
Metadata format and file structure |
||
|
Interoperability |
||
|
Process/Analyze |
Preparation and Pre-Processing Methods |
De-identification, anonymization |
|
Curation |
||
|
Software |
Commercial vs. custom |
|
|
Opensource vs. proprietary |
||
|
Share/Use/Reuse |
Publishing |
Repository |
|
Data paper |
||
|
Software |
||
|
Updates to datasets and new software versions |
||
|
Data linking |
||
|
Persistent identifier |
||
|
Metadata |
||
|
Integrity of data |
||
|
Peer review of datasets and metadata |
||
|
Reference data/digital objects in journal articles |
||
|
Curation |
||
|
Incentives for data publishing |
||
|
Mitigation of disincentives for data publishing |
||
|
Modes of Dissemination |
Traditional journal article |
|
|
Supplementary material |
||
|
On request |
||
|
Data landing page |
||
|
Workflow |
||
|
Mainstream media |
||
|
Social media |
||
|
Attribution |
Dataset citation |
|
|
Modes of Sharing |
Standardized formats |
|
|
Access |
Availability statement |
|
|
Mitigation of barriers and economic constraints |
||
|
Legal and Licenses |
Ownership |
|
|
Encouragement and support for sharing, use, and reuse |
||
|
Indigenous data rights |
||
|
Data sharing and licensing agreements |
||
|
Preserve/Discard |
Criteria for Preservation |
Use |
|
Impact |
||
|
Value |
||
|
Uniqueness |
||
|
Sustainability |
Longevity and support |
|
|
Funding models |
||
|
Moving Data from One Service to Another Across Organizations |
Roles and responsibilities |
|
|
Registry maintenance and curation |
||
|
Disciplinary archives |
||
|
Retention and Disposition Schedules |
End-of-life special considerations |
4.4 Curation and Stewardship
The processes and procedures to make research data shareable and reusable are typically referred to as curation and stewardship. Both curation and stewardship, and the job roles that are responsible for them, aim to collect, manage, preserve, and promote research data over their lifecycles. Curation is often performed by librarians and others outside of a laboratory or research group, while data stewards tend to work with a specific research group, lab, or department (i.e., a specific discipline) to ensure that they are embedded in research projects from the onset of the Plan lifecycle stage. Because curators tend to work outside of labs, they are typically engaged in research projects much later during the Share/Use/Reuse stage, which may introduce complications. The curation and stewardship theme implicitly touches each lifecycle stage.
Table 10 lists the topics and subtopics that are most relevant to the overarching theme of curation and stewardship.
Table 10. Curation and stewardship (overarching theme)
|
Lifecycle Stage |
Topic |
Subtopic |
|
Envision |
Data Governance – Strategic/Qualitative |
Data management organization |
|
Organization intent regarding FAIR data |
||
|
Stewardship |
||
|
Data Culture and Reward Structure |
Roles and responsibilities |
|
|
Recognition of data management |
||
|
Value of data workers |
||
|
Promotion and tenure |
||
|
Integrity of research and data |
||
|
FAIR data principles |
||
|
Incentives and impact for sharing and reuse |
||
|
Disincentives for sharing and reuse |
||
|
CARE and ethics |
||
|
Education and Workforce Development |
Workforce skills inventory |
|
|
Data management training |
||
|
Promotional paths and career development |
||
|
Resources—Allocation and Sustainability |
Staffing |
|
|
Community Engagement |
Stakeholder communities |
|
|
Partners/partnerships |
||
|
Engagement across knowledge domains and sectors |
||
|
Inclusivity in interactions |
||
|
Data services and the beneficiaries |
||
|
Plan |
Chain of Custody |
Roles and responsibilities |
|
Financial Aspects of Planning |
Staffing and training |
|
|
Data Management Planning |
Written data management plans (DMPs) |
|
|
Specification of data entities and actions throughout the lifecycle |
||
|
Machine-readable DMPs |
||
|
Data organization to facilitate future access |
||
|
Data management expertise and training |
||
|
FAIR |
Organizational support for making data more FAIR |
|
|
Identification of methods/guidelines vis-à-vis FAIR principles |
||
|
Research Data Standards |
Requirements and needs |
|
|
Sources of standards/guidelines for data/metadata |
||
|
Quality standards |
||
|
Community-based standards/conventions |
||
|
Assessment |
Metrics for tracking use and impact measures, including reuse |
|
|
Communication and Outreach |
Methods to share and reuse data/metadata |
|
|
Allocation of credit to project team members |
||
|
Promotion of data to communities of interest |
||
|
Cross-institution cooperation |
||
|
Requests for additional data from the research community |
||
|
Access Control Associated with Data Sensitivity |
Identification of responsible parties for access management |
|
|
Regulatory compliance |
||
|
Sensitive data/PII |
||
|
Limited disclosure, IP |
||
|
Licensing for reuse |
||
|
Generate/Acquire |
FAIR Principles |
Data made FAIR |
|
Guidelines/methodologies for each aspect: F, A, I, R |
||
|
Not FAIR data |
||
|
Community-Based Standards |
General vs. domain-specific |
|
|
Standards development organizations vs. community consensus |
||
|
Data format and file structure |
||
|
Metadata format and file structure |
||
|
Vocabulary and ontology |
||
|
Interoperability |
||
|
Process/Analyze |
Preparation and Pre-Processing Methods |
Curation |
|
Normalization of metadata |
||
|
Metadata |
Types of metadata |
|
|
Responsible parties |
||
|
Specification of metadata standards |
||
|
Linked data structure |
||
|
Persistent identifiers |
||
|
Provenance |
Original authoritative copy |
|
|
Version identification |
||
|
Derivative product |
||
|
Aggregation |
||
|
Subset |
||
|
Timestamp |
||
|
CrediT taxonomy |
||
|
Share/Use/Reuse |
Publishing |
Repository |
|
Data paper |
||
|
Software |
||
|
Updates to datasets and new software versions |
||
|
Data linking |
||
|
Persistent identifier |
||
|
Metadata |
||
|
Integrity of data |
||
|
Quality measures and assessment vis-à-vis fit for purpose |
||
|
Peer review of datasets and metadata |
||
|
Reference data/digital objects in journal articles |
||
|
Curation |
||
|
Publisher agreements and policies |
||
|
Incentives for data publishing |
||
|
Mitigation of disincentives for data publishing |
||
|
Attribution |
Citation metrics |
|
|
Citation impact |
||
|
Dataset citation |
||
|
Provenance |
||
|
Author identity management |
||
|
Use of persistent identifiers |
||
|
Versioning |
||
|
Modes of Sharing |
Standardized formats |
|
|
Interoperability tools |
||
|
Discovery platforms |
||
|
Catalogs |
||
|
Registries of repositories |
||
|
Access |
Internal access |
|
|
External access |
||
|
Programmatic access |
||
|
Virtual and physical enclaves |
||
|
Access vs. visiting |
||
|
Availability statement |
||
|
Mitigation of barriers and economic constraints |
||
|
Legal and Licenses |
Ownership |
|
|
Encouragement and support for sharing, use, and reuse |
||
|
Indigenous data rights |
||
|
Intellectual property rights/restrictions |
||
|
Usage agreements/terms/licenses and required permissions |
||
|
Standardized, machine-actionable license documents |
||
|
Citation requirements |
||
|
Levels of Protection |
Constraints and restrictions on data use and sharing |
|
|
Preserve/Discard |
Criteria for Preservation |
Use |
|
Impact |
||
|
Moving Data from One Service to Another Across Organizations |
Roles and responsibilities |
|
|
Registry maintenance and curation |
||
|
Disciplinary archives |
||
|
Retention and Disposition Schedules |
Technical decisions |
|
|
Administrative/policy decisions |
||
|
Deaccessioning/end-of-life |
||
|
End-of-life special considerations |
||
|
Recognition of removed data |
4.5 Data Quality
Data quality directly impacts a dataset’s fitness for purpose, usability, and reusability. All parties involved in every stage of a dataset’s lifecycle should be cognizant of data quality. The CODATA Research Data Management Terminology [5] definition of data quality includes the following attributes: accuracy, completeness, update status, relevance, consistency across data sources, reliability, appropriate presentation, and accessibility. Assessment of data quality is not a single process, but rather a series of actions that, over the lifetime of a dataset, collectively assure the greatest degree of quality.
Table 11 lists the topics and subtopics that are most relevant to the overarching theme of data quality.
Table 11. Data quality (overarching theme)
|
Lifecycle Stage |
Topic |
Subtopic |
|
Envision |
Data Governance – Strategic/Qualitative |
Purpose and value of data |
|
Stewardship |
||
|
Data Culture and Reward Structure |
Roles and responsibilities |
|
|
Education and Workforce Development |
Data management training |
|
|
Plan |
Research Data Standards |
Quality standards |
|
Generate/Acquire |
Generated Computational Data |
Verification/validation of output data |
|
Critically Evaluated (CE) Data |
Infrastructure to assure the greatest data integrity |
|
|
Process/Analyze |
Preparation and Pre-Processing Methods |
Data cleaning |
|
De-identification, anonymization |
||
|
Amputation and imputation |
||
|
Aggregation |
||
|
Validation and verification |
||
|
Normalization of metadata |
||
|
Software |
Testing and validation tools |
|
|
Documentation |
||
|
Share/Use/Reuse |
Publishing |
Integrity of data |
|
Quality measures and assessment vis-à-vis fit for purpose |
||
|
Modes of Sharing |
Standardized formats |
|
|
Preserve/Discard |
Criteria for Preservation |
Use |
|
Impact |
||
|
Value |
||
|
Uniqueness |
4.6 Data Standards
Data standards, both discipline-specific (e.g., Darwin Core [255] or NeXus [256]) and general (e.g., PREMIS [257] or schema.org [258]) are implemented by researchers to make their datasets both more FAIR and of higher quality. Researchers may use formal (e.g., ISO [259] or ANSI [260] standards) or de facto (e.g., DataCite [209]) standards for their research community. Use of data standards ensures consistency within a discipline and can reduce cost by decreasing the likelihood that data will have to be created again. Data standards are called out in every lifecycle stage except Envision.
Table 12 lists the topics and subtopics that are most relevant to the overarching theme of data standards.
Table 12. Data standards (overarching theme)
|
Lifecycle Stage |
Topic |
Subtopic |
|
Envision |
Data Governance – Strategic/Qualitative |
Stewardship |
|
Data Culture and Reward Structure |
Recognition of data management |
|
|
Integrity of research and data |
||
|
FAIR data principles |
||
|
Maintenance of FAIR data |
||
|
Education and Workforce Development |
Workforce skills inventory |
|
|
Data management training |
||
|
Community Engagement |
Engagement across knowledge domains and sectors |
|
|
Plan |
Data Management Planning |
Written data management plans (DMPs) |
|
Specification of data entities and actions throughout the lifecycle |
||
|
Machine-readable DMPs |
||
|
Data organization to facilitate future access |
||
|
Data management expertise and training |
||
|
Data Object |
Measurement |
|
|
Observation |
||
|
Survey |
||
|
Software |
||
|
Specimen (physical sample) |
||
|
FAIR |
Identification of methods/guidelines vis-à-vis FAIR principles |
|
|
Data/Metadata Considerations |
Criteria for selection of data/metadata |
|
|
Nature of data/metadata required |
||
|
Methods to capture and store data/metadata |
||
|
Metadata schema |
||
|
Data Architecture |
Model |
|
|
LIMS |
||
|
Interoperability among different architectures |
||
|
Existing standards |
||
|
Hardware and Software Infrastructure |
Interoperability |
|
|
Persistent instrument identifiers |
||
|
Research Data Standards |
Requirements and needs |
|
|
Sources of standards/guidelines for data/metadata |
||
|
Quality standards |
||
|
Community-based standards/conventions |
||
|
Generate/Acquire |
Data Types |
Measurement |
|
Text file |
||
|
Computation, simulation |
||
|
Source code |
||
|
Observation |
||
|
Survey |
||
|
Transaction |
||
|
Social media |
||
|
Acquired Data |
Provenance |
|
|
Critically Evaluated (CE) Data |
Infrastructure to assure the greatest data integrity |
|
|
FAIR Principles |
Data born FAIR |
|
|
Data made FAIR |
||
|
FAIR digital objects |
||
|
Guidelines/methodologies for each aspect: F, A, I, R |
||
|
Tools to capture FAIR provenance |
||
|
FAIR instruments and tools |
||
|
Community-Based Standards |
General vs. domain-specific |
|
|
Standards development organizations vs. community consensus |
||
|
Data format and file structure |
||
|
Metadata format and file structure |
||
|
Interoperability |
||
|
Process/Analyze |
Metadata |
Types of metadata |
|
Specification of metadata standards |
||
|
Linked data structure |
||
|
Persistent identifiers |
||
|
Provenance |
Original authoritative copy |
|
|
Version identification |
||
|
CrediT taxonomy |
||
|
Software |
Standards, protocols, and interfaces |
|
|
Share/Use/Reuse |
Publishing |
Persistent identifier |
|
Metadata |
||
|
Integrity of data |
||
|
Curation |
||
|
Attribution |
Citation metrics |
|
|
Dataset citation |
||
|
Provenance |
||
|
Author identity management |
||
|
Use of persistent identifiers |
||
|
Versioning |
||
|
Modes of Sharing |
Standardized formats |
|
|
Legal and Licenses |
Standardized, machine-actionable license documents |
|
|
Preserve/Discard |
Criteria for Preservation |
Provenance |
|
Storage and Preservation |
Methods to store and preserve data |
|
|
File integrity |
||
|
Moving Data from One Service to Another across Organizations |
Registry maintenance and curation |
|
|
Retention and Disposition Schedules |
End-of-life special considerations |
4.7 Diversity, Equity, Inclusion, and Accessibility
Diversity, equity, inclusion, and accessibility (DEIA) is a broad theme covering important social and cultural aspects of a research enterprise. Efforts in DEIA center on growing the sense of belonging for everyone in every laboratory, research group, department, or institution. Research data practices are not immune to biases and historical disadvantages must often be addressed through intentional action. DEIA is important not just for members of underrepresented and marginalized groups, but for the integrity of the research process as a whole. More inclusive research tends to be more rigorous as it introduces different perspectives that enable more complete and broader interpretations of research data. Given the typical challenges associated with cultural changes within an institution, DEIA efforts must be embedded throughout the research data management lifecycle to maximize their effectiveness.
Table 13 lists the topics and subtopics that are most relevant to the overarching theme of diversity, equity, inclusion, and accessibility.
Table 13. Diversity, equity, inclusion, and accessibility (overarching theme)
|
Lifecycle Stage |
Topic |
Subtopic |
|
Envision |
Data Governance – Strategic/Qualitative |
Vision and/or policy |
|
Organizational values, including DEIA |
||
|
Data Governance—Legal and Regulatory Compliance |
Ethics |
|
|
Social license for use and reuse |
||
|
Data Culture and Reward Structure |
Roles and responsibilities |
|
|
Recognition of data management |
||
|
Value of data workers |
||
|
CARE and ethics |
||
|
Education and Workforce Development |
Promotional paths and career development |
|
|
Community Engagement |
Stakeholder communities |
|
|
Partners/partnerships |
||
|
Engagement across knowledge domains and sectors |
||
|
Inclusivity in interactions |
||
|
Data services and the beneficiaries |
||
|
Plan |
Financial Aspects of Planning |
Staffing and training |
|
Data Management Planning |
Purpose/intent of research study and context of anticipated data use |
|
|
Data/Metadata Considerations |
Nature of data/metadata required |
|
|
Methods to capture and store data/metadata |
||
|
Hardware and Software Infrastructure |
Staff expertise and support staff |
|
|
Research Data Standards |
Community-based standards/conventions |
|
|
Assessment |
Goals/definition of success |
|
|
Metrics for tracking use and impact measures, including reuse |
||
|
Communication and Outreach |
Methods to share and reuse data/metadata |
|
|
Allocation of credit to project team members |
||
|
Promotion of data to communities of interest |
||
|
Cross-institution cooperation |
||
|
Requests for additional data from the research community |
||
|
Access Control Associated with Data Sensitivity |
Identification of responsible parties for access management |
|
|
Sensitive data/PII |
||
|
Generate/Acquire |
Data Sources |
In-house generation by researchers |
|
Remote generation by researchers |
||
|
In-field generation by researchers |
||
|
User facility generation by/for researchers |
||
|
Historical |
||
|
Human-annotated |
||
|
Qualitative Data |
Methods and protocols |
|
|
Data/metadata/paradata capture methods |
||
|
Acquired Data |
From collaborators |
|
|
From the literature |
||
|
Community-Based Standards |
General vs. domain-specific |
|
|
Standards development organizations vs. community consensus |
||
|
Process/Analyze |
Preparation and Pre-Processing Methods |
De-identification, anonymization |
|
Modeling |
ML, AI |
|
|
Metadata |
Responsible parties |
|
|
Provenance |
CrediT taxonomy |
|
|
Share/Use/Reuse |
Publishing |
Curation |
|
Incentives for data publishing |
||
|
Mitigation of disincentives for data publishing |
||
|
Attribution |
Author identity management |
|
|
Access |
External Access |
|
|
Mitigation of barriers and economic constraints |
||
|
Legal and Licenses |
Ownership |
|
|
Encouragement and support for sharing, use, and reuse |
||
|
Indigenous data rights |
||
|
Levels of Protection |
Unclassified but sensitive information |
|
|
Protection of limited data/secure platforms/enclaves |
||
|
Constraints and restrictions on data use and sharing |
||
|
Architectures for Application, Use, and Reuse |
Extensibility across communities, including machine-based interactions |
|
|
Preserve/Discard |
Criteria for Preservation |
Use |
|
Impact |
||
|
Value |
||
|
Uniqueness |
||
|
Retention and Disposition Schedules |
Deaccessioning/end-of-life |
|
|
End-of-life special considerations |
4.8 Ethics, Trust, and the CARE Principles
Ethics, trust, and the CARE principles encompass the ethical generation, analysis, use, reuse, sharing, disposal, and preservation of data and are pillars of responsible research that are called out throughout the framework. The phrase “as open as possible, as closed as necessary” [261] comes to mind when working through the ethical implications of sharing data. While ethical choices are often made at the Share/Use/Reuse lifecycle stage, questions and concerns regarding the generation or collection of data are likely to be examined by an institutional or ethics review board and must be considered in the Plan stage. In the Preserve/Discard stage, it is essential to comply with preservation and disposition standards. While the subtopics in the framework are a starting point for understanding how ethics touches every aspect of the research data lifecycle, it is also important that a project be securely grounded in the practices of a given discipline; for example, the standards for historical research will differ from those for economic or healthcare research.
Trust is a factor across the Framework and is the basis for relationships between data producers and users, the funding agencies that support projects, and the institutions that host research. Specific populations will also have various ethical considerations, for example, the CARE Principles for Indigenous Data Governance are quickly becoming the standard for working with indigenous data worldwide [262].
Table 14 lists the topics and subtopics that are most relevant to the overarching theme of ethics, trust, and the CARE principles.
Table 14. Ethics, trust, and the CARE principles (overarching theme)
|
Lifecycle Stage |
Topic |
Subtopic |
|
Envision |
Data Governance – Strategic/Qualitative |
Data management value proposition |
|
Stewardship |
||
|
Data Governance—Legal and Regulatory Compliance |
Ethics |
|
|
Sharing/licensing |
||
|
Data Culture and Reward Structure |
Roles and responsibilities |
|
|
Recognition of data management |
||
|
Value of data workers |
||
|
Promotion and tenure |
||
|
Integrity of research and data |
||
|
Incentives and impact for sharing and reuse |
||
|
Disincentives for sharing and reuse |
||
|
CARE and ethics |
||
|
Resources—Allocation and Sustainability |
Sources of funding |
|
|
Long-term funding |
||
|
Staffing |
||
|
Community Engagement |
Stakeholder communities |
|
|
Partners/partnerships |
||
|
Engagement across knowledge domains and sectors |
||
|
Inclusivity in interactions |
||
|
Plan |
Chain of Custody |
Roles and responsibilities |
|
Implementation authority |
||
|
Data Management Planning |
Written data management plans (DMPs) |
|
|
Purpose/intent of research study and context of anticipated data use |
||
|
Specification of data entities and actions throughout the lifecycle |
||
|
Data organization to facilitate future access |
||
|
Data management expertise and training |
||
|
Data Object |
Quantitative and qualitative |
|
|
Data/Metadata Considerations |
Methods to capture and store data/metadata |
|
|
Data Architecture |
Design |
|
|
Workflow |
||
|
Model |
||
|
Security |
||
|
Hardware and Software Infrastructure |
Security and privacy considerations |
|
|
Research Data Standards |
Requirements and needs |
|
|
Quality standards |
||
|
Community-based standards/conventions |
||
|
Communication and Outreach |
Allocation of credit to project team members |
|
|
Promotion of data to communities of interest |
||
|
Cross-institution cooperation |
||
|
Requests for additional data from the research community |
||
|
Access Control Associated with Data Sensitivity |
Identification of responsible parties for access management |
|
|
Sensitive data/PII |
||
|
Limited disclosure, IP |
||
|
Licensing for reuse |
||
|
Generate/Acquire |
Data Types |
Observation |
|
Survey |
||
|
Transaction |
||
|
Social media |
||
|
Data Sources |
In-house generation by researchers |
|
|
Remote generation by researchers |
||
|
In-field generation by researchers |
||
|
User facility generation by/for researchers |
||
|
Historical |
||
|
Human-annotated |
||
|
Generated Experimental Data |
Source of object/subjects |
|
|
Characteristics of object/subjects |
||
|
Conditions of research study |
||
|
Specification of instruments and tools |
||
|
Parameters for instruments and tools |
||
|
Methods, protocols, and calibration |
||
|
Data/metadata capture methods |
||
|
Reproducibility |
||
|
Generated Computational Data |
Input data/metadata |
|
|
Output data/metadata |
||
|
Data/metadata capture methods |
||
|
Qualitative Data |
Nature of object/subjects |
|
|
Methods and protocols |
||
|
Metadata |
||
|
Paradata |
||
|
Data/metadata/paradata capture methods |
||
|
Acquired Data |
From collaborators |
|
|
From repositories |
||
|
From the literature |
||
|
Aggregated datasets from multiple sources |
||
|
Restrictions, fees, and usage agreements |
||
|
Critically Evaluated (CE) Data |
Infrastructure to assure the greatest data integrity |
|
|
Single researcher dataset |
||
|
Aggregation of data evaluated by experts |
||
|
Reproducibility and uncertainty quantification |
||
|
Intellectual property rights |
||
|
Community-Based Standards |
General vs. domain-specific |
|
|
Standards development organizations vs. community consensus |
||
|
Data format and file structure |
||
|
Metadata format and file structure |
||
|
Interoperability |
||
|
Process/Analyze |
Preparation and Pre-Processing Methods |
Data cleaning |
|
De-identification, anonymization |
||
|
Curation |
||
|
Normalization of metadata |
||
|
Modeling |
Visualization |
|
|
ML, AI |
||
|
Metadata |
Responsible parties |
|
|
Persistent identifiers |
||
|
Provenance |
Original authoritative copy |
|
|
Version identification |
||
|
Derivative product |
||
|
Aggregation |
||
|
Subset |
||
|
Timestamp |
||
|
CrediT taxonomy |
||
|
Workflow and Middleware |
Decisions regarding the need for additional data |
|
|
Distributed workflow across sites |
||
|
Share/Use/Reuse |
Publishing |
Repository |
|
Data paper |
||
|
Metadata |
||
|
Integrity of data |
||
|
Peer review of datasets and metadata |
||
|
Curation |
||
|
Incentives for data publishing |
||
|
Mitigation of disincentives for data publishing |
||
|
Modes of Dissemination |
Traditional journal article |
|
|
Supplementary material |
||
|
On request |
||
|
Data landing page |
||
|
Workflow |
||
|
Mainstream media |
||
|
Social media |
||
|
Attribution |
Provenance |
|
|
Author identity management |
||
|
Access |
Internal access |
|
|
External access |
||
|
Programmatic access |
||
|
Virtual and physical enclaves |
||
|
Access vs. visiting |
||
|
Availability statement |
||
|
Mitigation of barriers and economic constraints |
||
|
Legal and Licenses |
Ownership |
|
|
Encouragement and support for sharing, use, and reuse |
||
|
Indigenous data rights |
||
|
Intellectual property rights/restrictions |
||
|
Usage agreements/terms/licenses and required permissions |
||
|
Data sharing and licensing agreements |
||
|
Service-level agreements |
||
|
Terms of service |
||
|
Standardized, machine-actionable license documents |
||
|
Citation requirements |
||
|
Levels of Protection |
Unclassified but sensitive information |
|
|
Protection of limited data/secure platforms/enclaves |
||
|
Constraints and restrictions on data use and sharing |
||
|
Anonymization |
||
|
Architectures for Application, Use, and Reuse |
Capture of insights from ML and use of these to improve datasets for future AI applications |
|
|
Preserve/Discard |
Criteria for Preservation |
Use |
|
Impact |
||
|
Value |
||
|
Uniqueness |
||
|
Cost |
||
|
Provenance |
||
|
Legal and regulatory |
||
|
Moving Data from One Service to Another Across Organizations |
Roles and responsibilities |
|
|
Registry maintenance and curation |
||
|
Disciplinary archives |
||
|
Retention and Disposition Schedules |
Administrative/policy decisions |
|
|
Deaccessioning/end-of-life |
||
|
End-of-life special considerations |
4.9 Legal Considerations
As much as technical capabilities structure the ways in which data can be gathered, created, published, and preserved, legal considerations constrain and channel the research data lifecycle. Laws form the background rules governing how data can be managed and shared. Legal considerations can be complex, as they are context-specific, hierarchical, and change over time. They typically vary by sector (e.g., healthcare, finance, education, and public government) and by geographic location (e.g., municipal, regional, national, and international), and are often subject to interpretation. Institutions that share data often use contracts and agreements that rely upon the legal system to order and enforce the terms therein. Laws sometimes restrict access, especially for categories of sensitive data such as personally identifiable information, certain types of healthcare information, and business identifiable information. However, laws can also enable data sharing by providing clear guidelines or directives to provide open data when it is in the public interest. Though legal considerations appear in most of the six lifecycle stages, meticulous planning and preparation make any constraints and compliance with policy requirements less onerous.
Table 15 lists the topics and subtopics that are most relevant to the overarching theme of legal considerations.
Table 15. Legal considerations (overarching theme)
|
Lifecycle Stage |
Topic |
Subtopic |
|
Envision |
Data Governance—Legal and Regulatory Compliance |
Privacy |
|
Safety and security assurance |
||
|
Risk assessment |
||
|
Risk mitigation and management |
||
|
Sharing/licensing |
||
|
Jurisdiction for sharing and reuse |
||
|
Data Culture and Reward Structure |
Disincentives for sharing and reuse |
|
|
Education and Workforce Development |
HR’s supporting role in workforce development and training |
|
|
Plan |
Chain of Custody |
Roles and responsibilities |
|
Hardware and Software Infrastructure |
Security and privacy considerations |
|
|
Access Control Associated with Data Sensitivity |
Identification of responsible parties for access management |
|
|
Ease of maintenance and implementation of records |
||
|
Regulatory compliance |
||
|
Sensitive data/PII |
||
|
Limited disclosure, IP |
||
|
Licensing for reuse |
||
|
Generate/Acquire |
Acquired Data |
Restrictions, fees, and usage agreements |
|
Critically Evaluated (CE) Data |
Intellectual property rights |
|
|
Process/Analyze |
Software |
Open source vs. proprietary |
|
Share/Use/Reuse |
Publishing |
Publisher agreements and policies |
|
Legal and Licenses |
Ownership |
|
|
Encouragement and support for sharing, use, and reuse |
||
|
Indigenous data rights |
||
|
Intellectual property rights/restrictions |
||
|
Usage agreements/terms/licenses and required permissions |
||
|
Data sharing and licensing agreements |
||
|
Service-level agreements |
||
|
Terms of service |
||
|
Standardized, machine-actionable license documents |
||
|
Citation requirements |
||
|
Levels of Protection |
Unclassified but sensitive information |
|
|
Security classification |
||
|
Protection of limited data/secure platforms/enclaves |
||
|
Constraints and restrictions on data use and sharing |
||
|
Anonymization |
||
|
Preserve/Discard |
Criteria for Preservation |
Legal and regulatory |
|
Retention and Disposition Schedules |
Administrative/policy decisions |
|
|
Deaccessioning/end-of-life |
||
|
Legal documents |
4.10 Metadata and Provenance
Metadata and provenance comprise the information about a dataset that defines, describes, and links the dataset to other datasets and provides contextualization of the dataset [91]. Metadata are essential to the effective use, reuse, and preservation of research data over time. In the Envision and Plan stages, metadata support legal and regulatory compliance, and are a consideration in planning data outputs and resources.
The table below shows each topic/subtopic that mentions or covers metadata. While the final lifecycle stage (Preserve/Discard) does not explicitly relate to metadata, the existence of descriptive and other metadata is imperative to this stage. The robustness of metadata for a file or dataset determines the level of curation needed for preservation and use: richer metadata allows for better findability, interoperability, and reuse in support of the FAIR data principles, while less robust metadata make all these activities more difficult and time intensive. Poor-quality metadata can render an otherwise important dataset unusable when the creator of the dataset is no longer available.
Included in the metadata theme is provenance, the historical information concerning the data [41]. Understanding the provenance of a given dataset, including metadata on the experimental conditions used to generate the data, is essential for many disciplines. Without proper provenance documentation, it is difficult to assess the quality and reliability of the data and to publish them with correct metadata. Provenance can be used as a criterion for preservation.
Table 16 lists the topics and subtopics that are most relevant to the overarching theme of metadata and provenance.
Table 16. Metadata and provenance (overarching theme)
|
Lifecycle Stage |
Topic |
Subtopic |
|
Envision |
Data Governance – Strategic/Qualitative |
End-use support |
|
Stewardship |
||
|
Data Governance – Legal and Regulatory Compliance |
Inventory |
|
|
Sharing/licensing |
||
|
Data Culture and Reward Structure |
FAIR data principles |
|
|
Maintenance of FAIR data |
||
|
Education and Workforce Development |
Data management training |
|
|
Plan |
Chain of Custody |
Roles and responsibilities |
|
Implementation authority |
||
|
Centralized inventory of services, groups, and resources |
||
|
Provenance |
||
|
Data Management Planning |
Specification of data entities and actions throughout the lifecycle |
|
|
Machine-readable DMPs |
||
|
FAIR |
Identification of methods/guidelines vis-à-vis FAIR principles |
|
|
Data/Metadata Considerations |
Criteria for selection of data/metadata |
|
|
Nature of data/metadata required |
||
|
Methods to capture and store data/metadata |
||
|
Metadata schema |
||
|
Data Architecture |
Model |
|
|
LIMS |
||
|
Hardware and Software Infrastructure |
Persistent instrument identifiers |
|
|
Research Data Standards |
Requirements and needs |
|
|
Sources of standards/guidelines for data/metadata |
||
|
Community-based standards/conventions |
||
|
Communication and Outreach |
Methods to share and reuse data/metadata |
|
|
Allocation of credit to project team members |
||
|
Access Control Associated with Data Sensitivity |
Regulatory compliance |
|
|
Sensitive data/PII |
||
|
Limited disclosure, IP |
||
|
Generate/Acquire |
Generated Experimental Data |
Data/metadata capture methods |
|
Provenance and capture methods |
||
|
Reproducibility |
||
|
Generated Computational Data |
Versioning |
|
|
Data/metadata capture methods |
||
|
Provenance and capture methods |
||
|
Qualitative Data |
Metadata |
|
|
Paradata |
||
|
Data/metadata/paradata capture methods |
||
|
Acquired Data |
Provenance |
|
|
Restrictions, fees, and usage agreements |
||
|
Critically Evaluated (CE) Data |
Reproducibility and uncertainty quantification |
|
|
Intellectual property rights |
||
|
FAIR Principles |
Data born FAIR |
|
|
Data made FAIR |
||
|
FAIR digital objects |
||
|
Tools to capture FAIR provenance |
||
|
FAIR instruments and tools |
||
|
Community-Based Standards |
Metadata format and file structure |
|
|
Vocabulary and ontology |
||
|
Process/Analyze |
Preparation and Pre-Processing Methods |
Curation |
|
Normalization of metadata |
||
|
Metadata |
Types of metadata |
|
|
Responsible parties |
||
|
Specification of metadata standards |
||
|
Linked data structure |
||
|
Persistent identifiers |
||
|
Provenance |
Original authoritative copy |
|
|
Version identification |
||
|
Derivative products |
||
|
Aggregation |
||
|
Subset |
||
|
Timestamp |
||
|
CrediT taxonomy |
||
|
Workflow and Middleware |
Tools for automated metadata capture |
|
|
Share/Use/Reuse |
Publishing |
Repository |
|
Data linking |
||
|
Persistent identifier |
||
|
Metadata |
||
|
Peer review of datasets and metadata |
||
|
Curation |
||
|
Publisher agreements and policies |
||
|
Modes of Dissemination |
Data landing page |
|
|
Attribution |
Provenance |
|
|
Author identity management |
||
|
Use of persistent identifiers |
||
|
Versioning |
||
|
Modes of Sharing |
Catalogs |
|
|
Registries of repositories |
||
|
Legal and Licenses |
Usage agreements/terms/licenses and required permissions |
|
|
Data sharing and licensing agreements |
||
|
Preserve/Discard |
Criteria for Preservation |
Provenance |
|
Legal and Regulatory |
||
|
Retention and Disposition Schedules |
Deaccessioning/end-of-life |
|
|
Recognition of removed data |
4.11 Reproducibility and the FAIR Data Principles
Touching many of the lifecycle stages are reproducibility and the FAIR data principles, which are findability, accessibility, interoperability, and reusability. Reproducible research yields data that can be replicated by the author or other researchers using only information provided in the original work [84]. Standards for reproducibility differ by research discipline, but typically the metadata and other contextual information needed for reproducibility are similar to those described by the FAIR data principles [33]. These community-based principles have come to define, for many disciplines, the state to which a published dataset should aspire. By keeping the principles of findability, accessibility, interoperability, and reusability in mind while planning a project or when data are collected, the data will be ready for broader reuse when they are publicly released. Extensions of the FAIR data principles also exist, such as FAIRER, which adds Ethical and Revisable to the base principles [263].
Table 17 lists the topics and subtopics that are most relevant to the overarching theme of reproducibility and the FAIR data principles.
Table 17. Reproducibility and the FAIR data principles (overarching theme)
|
Lifecycle Stage |
Topic |
Subtopic |
|
Envision |
Data Governance – Strategic/Qualitative |
Stewardship |
|
Data Governance—Legal and Regulatory Compliance |
Sharing/licensing |
|
|
Social license for use and reuse |
||
|
Data Culture and Reward Structure |
FAIR data principles |
|
|
Maintenance of FAIR data |
||
|
Community Engagement |
Engagement across knowledge domains and sectors |
|
|
Plan |
Data Management Planning |
Data organization to facilitate future access |
|
FAIR |
Organizational support for making data more FAIR |
|
|
Identification of methods/guidelines vis-à-vis FAIR principles |
||
|
Data/Metadata Considerations |
Intended extent of FAIRness |
|
|
Metadata schema |
||
|
Hardware and Software Infrastructure |
Interoperability |
|
|
Persistent instrument identifiers |
||
|
Research Data Standards |
Requirements and needs |
|
|
Community-based standards/conventions |
||
|
Assessment |
Metrics for tracking use and impact measures, including reuse |
|
|
Communication and Outreach |
Methods to share and reuse data/metadata |
|
|
Access Control Associated with Data Sensitivity |
Identification of responsible parties for access management |
|
|
Ease of maintenance and implementation of records |
||
|
Limited disclosure, IP |
||
|
Licensing for reuse |
||
|
Generate/Acquire |
FAIR Principles |
Data born FAIR |
|
Data made FAIR |
||
|
FAIR digital objects |
||
|
FAIR on a continuous scale |
||
|
Guidelines/methodologies for each aspect: F, A, I, R |
||
|
Tools to capture FAIR provenance |
||
|
FAIR instruments and tools |
||
|
Not FAIR data |
||
|
Community-Based Standards |
Metadata format and file structure |
|
|
Interoperability |
||
|
Process/Analyze |
Metadata |
Types of metadata |
|
Specification of metadata standards |
||
|
Persistent identifiers |
||
|
Share/Use/Reuse |
Publishing |
Repository |
|
Data linking |
||
|
Persistent identifier |
||
|
Metadata |
||
|
Modes of Sharing |
Standardized formats |
|
|
Interoperability tools |
||
|
Discovery platforms |
||
|
Registries of repositories |
||
|
Access |
Internal access |
|
|
External access |
||
|
Programmatic access |
||
|
Legal and Licenses |
Intellectual property rights/restrictions |
|
|
Usage agreements/terms/licenses and required permissions |
||
|
Data sharing and licensing agreements |
||
|
Standardized, machine-actionable license documents |
4.12 Security and Privacy
Digital data are designed to be easily shared, copied, and transformed, but their mobility can make privacy and security difficult to ensure. Security and privacy issues are fundamentally about trust, both in the institutions and systems that facilitate collection, storage, and transfer of data, as well as the individuals within those institutions. Proper protocols, rationally based on the need to protect vulnerable populations or sensitive information, or stemming from common understandings of security needs, promote trust, which can enable greater data mobility. In the European Union, organizations that collect, store, or hold personal data must comply with the General Data Protection Regulation. [264] The U.S. does not have such a universal regulation, though various federal laws govern different sectors and types of data, and some states have their own additional regulations. Security and privacy issues arise in the Envision and Plan lifecycle stages, with the results folded into the day-to-day procedures for handling and accessing data and appear again in the Share/Use/Reuse lifecycle stage.
Table 18 lists the topics and subtopics that are most relevant to the overarching theme of security and privacy.
Table 18. Security and privacy (overarching theme)
|
Lifecycle Stage |
Topic |
Subtopic |
|
Envision |
Data Governance—Strategic/Qualitative |
Data management organization |
|
Organizational values, including DEIA |
||
|
Data Governance—Legal and Regulatory Compliance |
Privacy |
|
|
Safety and security assurance |
||
|
Education and Workforce Development |
Workforce skills inventory |
|
|
Plan |
Data Architecture |
Hosting and storage, cloud storage |
|
Security |
||
|
Hardware and Software Infrastructure |
Security and privacy considerations |
|
|
Access Control Associated with Data Sensitivity |
Identification of responsible parties for access management |
|
|
Ease of maintenance and implementation of records |
||
|
Regulatory compliance |
||
|
Sensitive data/PII |
||
|
Limited disclosure, IP |
||
|
Licensing for reuse |
||
|
Process/Analyze |
Software |
Security and software updates |
|
Share/Use/Reuse |
Access |
Internal access |
|
External access |
||
|
Programmatic access |
||
|
Virtual and physical enclaves |
||
|
Access vs. visiting |
||
|
Availability statement |
||
|
Mitigation of barriers and economic constraints |
||
|
Legal and Licenses |
Indigenous data rights |
|
|
Intellectual property rights/restrictions |
||
|
Levels of Protection |
Unclassified but sensitive information |
|
|
Security classification |
||
|
Protection of limited data/secure platforms/enclaves |
||
|
Constraints and restrictions on data use and sharing |
||
|
Anonymization |
4.13 Software Tools
Regarding research data, software tools are programs or utilities for developing applications and analyzing/processing or searching for data. Additionally, software tools are used to generate data from computational and experimental methods, throughout the publication process. An exhaustive list of tools would be ever-changing; more important than a list of tools used in every discipline is the understanding that the tools used during all lifecycle stages can influence other stages.
Table 19 lists the topics and subtopics that are most relevant to the overarching theme of software tools.
Table 19. Software tools (overarching theme)
|
Lifecycle Stage |
Topic |
Subtopic |
|
Envision |
Education and Workforce Development |
Workforce preparedness in new and advanced technologies |
|
Plan |
Financial Aspects of Planning |
Staffing and training |
|
Data Management Planning |
Machine-readable DMPs |
|
|
Data Object |
Software |
|
|
Data Architecture |
LIMS |
|
|
Hosting and storage, cloud storage |
||
|
Hardware and Software Infrastructure |
Organizational research needs |
|
|
Tools to support data-related processes |
||
|
Models that connect infrastructure to data processes and workflow |
||
|
Interoperability |
||
|
Persistent instrument identifiers |
||
|
Sustainability of data vis-à-vis obsolete infrastructure |
||
|
Generate/Acquire |
Data Types |
Computation, simulation |
|
Source code |
||
|
Generated Experimental Data |
Specification of instruments and tools |
|
|
Parameters for instruments and tools |
||
|
Methods, protocols, and calibration |
||
|
Data/metadata capture methods |
||
|
Generated Computational Data |
Parameters and conditions for computation |
|
|
Acquisition Software |
Open source vs. proprietary |
|
|
LIMS |
||
|
Instrument control |
||
|
Electronic laboratory notebook |
||
|
Process/Analyze |
Modeling |
Visualization |
|
Integrated development environment |
||
|
Software |
Commercial vs. custom |
|
|
Open source vs. proprietary |
||
|
Aggregation tools |
||
|
Surveying tools |
||
|
Statistical tools |
||
|
Calculation and analysis tools |
||
|
APIs |
||
|
Database management tools |
||
|
Testing and validation tools |
||
|
Versioning and maintenance |
||
|
Source code repository |
||
|
Security and software updates |
||
|
Standards, protocols, and interfaces |
||
|
Workflow and Middleware |
LIMS |
|
|
Laboratory notebook |
||
|
Tools for automated metadata capture |
||
|
Anomaly detection and correction tools |
||
|
Collaboration tools |
||
|
Process monitoring and evaluation |
||
|
Containerization |
||
|
Reusable workflow components |
||
|
Microservices |
||
|
Share/Use/Reuse |
Publishing |
Software |
|
Updates to datasets and new software versions |
||
|
Legal and Licenses |
Usage agreements/terms/licenses and required permissions |
4.14 Training, Education, and Workforce Development
Training, education, and workforce development are critical for ensuring that any given organization or individual involved in the research data management process has the necessary skills for RDM. Investment into workforce development is especially important in an area where best practices are still developing. On-the-job training not only helps to promote the standardization that is important in RDM but can also promote equity by ensuring that everyone has access to the most innovative practices.
Table 20 lists the topics and subtopics that are most relevant to the overarching theme of training, education, and workforce development.
Table 20. Training, education, and workforce development (overarching theme)
|
Lifecycle Stage |
Topic |
Subtopic |
|
Envision |
Data Culture and Reward Structure |
Value of data workers |
|
Promotion and tenure |
||
|
Education and Workforce Development |
Workforce skills inventory |
|
|
Workforce preparedness in new and advanced technologies |
||
|
Data management training |
||
|
HR’s supporting role in workforce development and training |
||
|
Promotional paths and career development |
||
|
Resources—Allocation and Sustainability |
Staffing |
|
|
Community Engagement |
Engagement across knowledge domains and sectors |
|
|
Plan |
Financial Aspects of Planning |
Staffing and training |
|
Data Management Planning |
Data management expertise and training |
|
|
FAIR |
Identification of methods/guidelines vis-à-vis FAIR principles |
|
|
Hardware and Software Infrastructure |
Staff expertise and support staff |
|
|
Generate/Acquire |
Community-Based Standards |
General vs. domain-specific |
|
Standards development organizations vs. community consensus |
||
|
Data format and file structure |
||
|
Metadata format and file structure |
||
|
Vocabulary and ontology |
||
|
Interoperability |
5 Profiles
Profiles specify those topics and subtopics in the RDaF lifecycle stages that are most relevant for a particular job role or research data management (RDM) function in an organization. The framework contains a comprehensive list of the tasks and issues that may arise with respect to research data activities and RDM. Most organizations or individuals will not find every subtopic to be relevant. As described below, NIST is developing a tool that allows individuals and organizations to customize a profile (i.e., select relevant subtopics from the full list of subtopics) for their specific needs or responsibilities.
The RDaF team generated sample profiles for eight common RDM job roles or functions. These profiles described below are intended to serve as samples and guides. Users may either modify a sample profile as a starting point for their own profile or build an entirely new profile by selecting relevant subtopics. The subtopics relevant to the eight sample profiles are presented in Table 21. A straightforward tool to generate a customized profile—by modifying one of the sample profiles or by creating an entirely new profile—is described in Appendix D. The tool is an editable Excel file that contains all the information in Table 21 and a blank template of all the subtopics. Profiles may also be used to conduct self-assessments of RDM and identify tasks and issues that may need attention. Results of such self-assessments can subsequently be communicated within an organization or between organizations.
AI expert – This profile addresses the growing and evolving field of artificial intelligence. Experts in AI and machine learning often deal with large and incomplete datasets and may not be the originators of the data, making it difficult, e.g., to assess data and metadata quality.
Budget/cost expert – This profile is relevant to those individuals whose job responsibilities encompass budgetary and financial issues, such as securing funding, distributing funds and tracking spending within an organization. Budgetary issues underlie nearly every subtopic; this profile focuses on those subtopics that drive RDM costs.
Curator – This profile is pertinent to individuals who curate data in general, such as data librarians, and to individuals who curate data only for a specific research project. Curators collect, organize, clean, annotate, and transform data, which are critical tasks for data preservation, use, and reuse.
Data/IT leader – This profile is relevant to those individuals who establish priorities for RDM at an organizational or disciplinary level and who engage in strategic planning and establishing RDM infrastructure requirements.
Provider of data tools – This profile is germane to those individuals who create and provide tools that enable data to be collected, analyzed, stored, and shared such as hardware providers and programmers.
Publisher – This profile is pertinent to those individuals who publish articles in scientific journals and datasets in various dissemination modes These individuals and their organizations are concerned with data access, storage, preservation, and evaluation of data quality in publishing decisions.
Research organization leader – This profile is relevant to those individuals who establish policies, procedures, and processes for managing research data across an organization.
Researcher – This profile is germane to those individuals who conduct scholarly studies in all disciplines, including the social sciences and humanities, to produce new data used to, e.g., increase knowledge, validate hypotheses, and facilitate decision-making.
|
Envision: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Data Governance – Strategic/Qualitative |
Identification of goals and roles |
X |
X |
X |
X |
X |
X |
X |
||
|
Vision and/or policy |
X |
X |
X |
X |
X |
|||||
|
Data management organization |
X |
X |
X |
X |
||||||
|
Organizational values, including DEIA |
X |
X |
X |
X |
||||||
|
Data management value proposition |
X |
X |
X |
X |
X |
|||||
|
Data needs assessment |
X |
X |
X |
X |
X |
|||||
|
Purpose and value of data |
X |
X |
X |
X |
X |
X |
X |
|||
|
Organization intent regarding FAIR data |
X |
X |
X |
X |
X |
|||||
|
End-use support |
X |
X |
X |
|||||||
|
Stewardship |
X |
X |
X |
X |
||||||
|
Data Governance – Legal and Regulatory Compliance |
Privacy |
X |
X |
X |
X |
|||||
|
Ethics |
X |
X |
X |
X |
X |
X |
X |
|||
|
Safety and security assurance |
X |
X |
X |
X |
||||||
|
Inventory |
X |
X |
||||||||
|
Risk assessment |
X |
X |
X |
|||||||
|
Risk mitigation and management |
X |
X |
X |
X |
||||||
|
Sharing/licensing |
X |
X |
X |
X |
X |
|||||
|
Social license for use and reuse |
X |
X |
X |
X |
||||||
|
Jurisdiction for sharing and reuse |
X |
X |
||||||||
|
Envision: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Data Culture and Reward Structure |
Roles and responsibilities |
X |
X |
X |
X |
X |
||||
|
Recognition of data management |
X |
X |
X |
X |
X |
X |
||||
|
Value of data workers |
X |
X |
X |
|||||||
|
Promotion and tenure |
X |
X |
X |
|||||||
|
Integrity of research and data |
X |
X |
X |
|||||||
|
FAIR data principles |
X |
X |
X |
X |
X |
|||||
|
Maintenance of FAIR data |
X |
X |
X |
X |
X |
X |
||||
|
Incentives and impact for sharing and reuse |
X |
X |
X |
X |
X |
X |
||||
|
Disincentives for sharing and reuse |
X |
X |
X |
|||||||
|
CARE and ethics |
X |
X |
X |
X |
||||||
|
Education and Workforce Development |
Workforce skills inventory |
X |
X |
|||||||
|
Workforce preparedness in new and advanced technologies |
X |
X |
X |
X |
||||||
|
Data management training |
X |
X |
X |
X |
X |
|||||
|
HR’s supporting role in workforce development and training |
||||||||||
|
Promotional paths and career development |
X |
X |
X |
|||||||
|
Resources—Allocation and Sustainability |
Sources of funding |
X |
X |
|||||||
|
Long-term funding |
X |
X |
||||||||
|
Staffing |
X |
X |
X |
|||||||
|
Community Engagement |
Stakeholder communities |
X |
X |
X |
X |
X |
||||
|
Modes of communication |
X |
X |
X |
|||||||
|
Partners/partnerships |
X |
X |
X |
X |
||||||
|
Engagement across knowledge domains and sectors |
X |
X |
X |
X |
||||||
|
Inclusivity in interactions |
X |
X |
X |
|||||||
|
Data services and the beneficiaries |
X |
X |
X |
|||||||
|
Plan: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Chain of Custody |
Roles and responsibilities |
X |
X |
X |
X |
|||||
|
Implementation authority |
X |
X |
||||||||
|
Centralized inventory of services, groups, and resources |
X |
X |
X |
|||||||
|
Provenance |
X |
X |
||||||||
|
Financial Aspects of Planning |
Funding models for provisioning resources |
X |
X |
|||||||
|
Funding sources |
X |
X |
X |
|||||||
|
Decision-making tools to assess costs |
X |
|||||||||
|
Cost-benefit analysis |
X |
X |
X |
|||||||
|
Cost breakdown by lifecycle stage |
X |
X |
||||||||
|
Downstream lifecycle costs |
X |
X |
X |
|||||||
|
Staffing and training |
X |
X |
X |
|||||||
|
Data Management Planning |
Written data management plans (DMPs) |
X |
X |
X |
X |
|||||
|
Purpose/intent of research study and context of anticipated data use |
X |
X |
X |
|||||||
|
Plan: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Data Management Planning |
Specification of data entities and actions throughout the lifecycle |
X |
X |
|||||||
|
Machine-readable DMPs |
X |
|||||||||
|
Linkage of DMPs to administrative records |
X |
X |
||||||||
|
Data organization to facilitate future access |
X |
X |
X |
X |
X |
X |
||||
|
Data management expertise and training |
X |
X |
X |
X |
||||||
|
Data Object |
Quantitative and qualitative |
X |
X |
|||||||
|
Measurement |
X |
X |
||||||||
|
Observation |
X |
X |
||||||||
|
Survey |
X |
X |
||||||||
|
Software |
X |
X |
X |
|||||||
|
Model |
X |
X |
X |
X |
||||||
|
Documentation (text) |
X |
X |
X |
|||||||
|
Specimen (physical sample) |
X |
|||||||||
|
Presentation |
X |
X |
X |
|||||||
|
FAIR |
Organizational support for making data more FAIR |
X |
X |
X |
X |
|||||
|
Identification of methods/guidelines vis-à-vis FAIR principles |
X |
X |
X |
X |
||||||
|
Plan: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Data/Metadata Considerations |
Criteria for selection of data/metadata |
X |
X |
X |
||||||
|
Nature of data/metadata required |
X |
X |
||||||||
|
Intended extent of FAIRness |
X |
X |
||||||||
|
Methods to capture and store data/metadata |
X |
X |
||||||||
|
Metadata schema |
X |
X |
||||||||
|
Data Architecture |
Design |
X |
X |
X |
||||||
|
Processing operations |
X |
|||||||||
|
Workflow |
X |
|||||||||
|
Model |
||||||||||
|
LIMS |
||||||||||
|
Hosting and storage, cloud storage |
X |
X |
||||||||
|
Configuration management |
X |
|||||||||
|
Interoperability among different architectures |
X |
X |
||||||||
|
Security |
X |
X |
X |
|||||||
|
Existing standards |
X |
X |
||||||||
|
Hardware and Software |
Organizational research needs |
X |
X |
X |
||||||
|
Tools to support data-related processes |
X |
X |
||||||||
|
Models that connect infrastructure to data processes and workflow |
X |
|||||||||
|
Interoperability |
X |
|||||||||
|
Persistent instrument identifiers |
X |
|||||||||
|
Plan: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Hardware and Software |
Sustainability of data vis-à-vis obsolete infrastructure |
X |
X |
|||||||
|
Security and privacy considerations |
X |
X |
||||||||
|
Staff expertise and support staff |
X |
X |
||||||||
|
Research Data Standards |
Requirements and needs |
X |
X |
X |
||||||
|
Sources of standards/guidelines for data/metadata |
X |
X |
X |
|||||||
|
Quality standards |
X |
X |
X |
|||||||
|
Community-based standards/conventions |
X |
X |
X |
X |
||||||
|
Assessment |
Goals/definition of success |
X |
X |
X |
X |
|||||
|
Metrics for tracking use and impact measures, including reuse |
X |
X |
X |
X |
||||||
|
Communication and Outreach |
Methods to share and reuse data/metadata |
X |
X |
X |
X |
|||||
|
Allocation of credit to project team members |
X |
X |
||||||||
|
Promotion of data to communities of interest |
X |
X |
X |
|||||||
|
Cross-institution cooperation |
X |
X |
X |
X |
X |
|||||
|
Requests for additional data from the research community |
X |
X |
X |
|||||||
|
Access Control Associated with Data Sensitivity |
Identification of responsible parties for access management |
X |
X |
|||||||
|
Ease of maintenance and implementation of records |
X |
|||||||||
|
Regulatory compliance |
X |
X |
X |
X |
||||||
|
Sensitive data/PII |
X |
X |
X |
|||||||
|
Limited disclosure/, IP |
X |
X |
X |
|||||||
|
Licensing for reuse |
X |
X |
||||||||
|
Generate/Acquire: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Data Types |
Measurement |
X |
X |
X |
X |
|||||
|
Text file |
X |
X |
X |
X |
||||||
|
Computation, simulation |
X |
X |
X |
X |
||||||
|
Source code |
X |
X |
X |
|||||||
|
Observation |
X |
X |
X |
|||||||
|
Survey |
X |
X |
||||||||
|
Transaction |
X |
X |
||||||||
|
Social media |
X |
X |
||||||||
|
Data Sources |
In-house generation by researchers |
X |
X |
X |
X |
|||||
|
Remote generation by researchers |
X |
X |
X |
|||||||
|
In-field generation by researchers |
X |
X |
||||||||
|
User facility generation by/for researchers |
X |
X |
X |
|||||||
|
Historical |
X |
X |
||||||||
|
Human-annotated |
X |
X |
||||||||
|
Generated Experimental Data |
Source of objects/subjects |
X |
||||||||
|
Characteristics of objects/subjects |
X |
|||||||||
|
Conditions of research study |
X |
X |
||||||||
|
Generate/Acquire: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Generated Experimental Data |
Specification of instruments and tools |
X |
X |
X |
||||||
|
Parameters for instruments and tools |
X |
X |
X |
|||||||
|
Methods, protocols, and calibration |
X |
X |
||||||||
|
Data/metadata capture methods |
X |
X |
||||||||
|
Provenance and capture methods |
X |
X |
||||||||
|
Reproducibility |
X |
X |
X |
X |
||||||
|
Generated Computational Data |
Input data/metadata |
X |
X |
X |
X |
|||||
|
Output data/metadata |
X |
X |
X |
|||||||
|
Hardware |
X |
|||||||||
|
Parameters and conditions for computation |
X |
X |
||||||||
|
Versioning |
X |
X |
X |
|||||||
|
Data/metadata capture methods |
X |
X |
X |
|||||||
|
Provenance and capture methods |
X |
X |
||||||||
|
Verification/validation of output data |
X |
X |
X |
|||||||
|
Qualitative Data |
Nature of objects/subjects |
X |
||||||||
|
Methods and protocols |
X |
|||||||||
|
Metadata |
X |
|||||||||
|
Paradata |
X |
|||||||||
|
Data/metadata/paradata capture methods |
X |
|||||||||
|
Generate/Acquire: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Acquired Data |
From collaborators |
X |
X |
X |
X |
|||||
|
From repositories |
X |
X |
X |
|||||||
|
From the literature |
X |
X |
X |
|||||||
|
Aggregated datasets from multiple sources |
X |
X |
X |
|||||||
|
Provenance |
X |
X |
||||||||
|
Restrictions, fees, and usage agreements |
X |
X |
||||||||
|
Critically Evaluated (CE) Data |
Infrastructure to assure the greatest data integrity |
X |
X |
|||||||
|
Single researcher dataset |
X |
X |
||||||||
|
Aggregation of data evaluated by experts |
X |
X |
X |
X |
||||||
|
Reproducibility and uncertainty quantification |
X |
X |
||||||||
|
Intellectual property rights |
X |
|||||||||
|
FAIR Principles |
Data born FAIR |
X |
X |
X |
X |
X |
||||
|
Data made FAIR |
X |
X |
X |
X |
X |
X |
||||
|
FAIR digital objects |
X |
X |
X |
|||||||
|
FAIR on a continuous scale |
X |
X |
||||||||
|
Guidelines/methodologies for each aspect: F, A, I, R |
X |
X |
X |
X |
X |
|||||
|
Tools to capture FAIR provenance |
X |
X |
X |
X |
||||||
|
FAIR instruments and tools |
X |
X |
X |
|||||||
|
Not FAIR data |
X |
X |
X |
X |
||||||
|
Generate/Acquire: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Community-Based Standards |
General vs. domain-specific |
X |
X |
X |
X |
|||||
|
Standards development organizations vs. community consensus |
X |
X |
X |
|||||||
|
Data format and file structure |
X |
X |
X |
X |
X |
|||||
|
Metadata format and file structure |
X |
X |
X |
X |
X |
|||||
|
Vocabulary and ontology |
X |
X |
X |
|||||||
|
Interoperability |
X |
X |
X |
X |
X |
|||||
|
Acquisition Software |
Open source vs. proprietary |
X |
X |
|||||||
|
LIMS |
X |
|||||||||
|
Instrument control |
X |
|||||||||
|
Electronic laboratory notebook |
X |
X |
||||||||
|
Audio and video recording |
X |
|||||||||
|
Process/Analyze: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Types of Processed Data |
Tables, spreadsheets |
X |
X |
X |
X |
X |
||||
|
Charts, graphs |
X |
X |
X |
X |
X |
|||||
|
Maps, vectors, images |
X |
X |
X |
X |
X |
|||||
|
Instrument outputs |
X |
X |
X |
|||||||
|
Dynamic data |
X |
X |
||||||||
|
Datasets from models and simulations |
X |
X |
X |
X |
X |
|||||
|
Structured data |
X |
X |
X |
X |
||||||
|
Process/Analyze: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Preparation and Pre-Processing Methods |
Data cleaning |
X |
X |
X |
X |
X |
||||
|
De-identification, anonymization |
X |
X |
X |
|||||||
|
Amputation and imputation |
X |
X |
X |
X |
||||||
|
Aggregation |
X |
X |
X |
X |
X |
|||||
|
Validation and verification |
X |
X |
X |
X |
X |
|||||
|
Curation |
X |
X |
X |
X |
X |
X |
||||
|
Normalization of metadata |
X |
X |
X |
X |
X |
X |
X |
|||
|
Analysis Methods |
Manual |
X |
X |
X |
X |
|||||
|
Exploratory |
X |
X |
X |
X |
X |
|||||
|
Descriptive |
X |
X |
X |
X |
||||||
|
Diagnostic |
X |
X |
X |
X |
||||||
|
Evaluative |
X |
X |
X |
X |
||||||
|
Predictive |
X |
X |
X |
|||||||
|
Prescriptive |
X |
X |
||||||||
|
Correlational |
X |
X |
X |
|||||||
|
Statistical |
X |
X |
X |
X |
||||||
|
Automated, autonomous |
X |
X |
X |
|||||||
|
Modeling |
Visualization |
X |
X |
X |
X |
X |
||||
|
ML, AI |
X |
X |
X |
X |
X |
X |
||||
|
Iterative model fitting |
X |
X |
X |
|||||||
|
Integrated development environment |
X |
X |
X |
X |
X |
|||||
|
Process/Analyze: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Metadata |
Types of metadata |
X |
X |
X |
X |
X |
X |
|||
|
Responsible parties |
X |
X |
X |
X |
||||||
|
Specification of metadata standards |
X |
X |
X |
X |
X |
|||||
|
Linked data structure |
X |
X |
X |
|||||||
|
Persistent identifiers |
X |
X |
X |
X |
X |
X |
||||
|
Provenance |
Original authoritative copy |
X |
X |
X |
X |
X |
X |
|||
|
Version identification |
X |
X |
X |
X |
X |
X |
X |
|||
|
Derivative product |
X |
X |
X |
X |
||||||
|
Aggregation |
X |
X |
X |
X |
||||||
|
Subset |
X |
X |
X |
X |
X |
|||||
|
Timestamp |
X |
X |
X |
X |
||||||
|
CRediT taxonomy |
X |
X |
X |
|||||||
|
Software |
Commercial vs. custom |
X |
X |
X |
X |
X |
||||
|
Open source vs. proprietary |
X |
X |
X |
X |
X |
X |
||||
|
Aggregation tools |
X |
X |
||||||||
|
Surveying tools |
X |
X |
||||||||
|
Statistical tools |
X |
X |
X |
X |
||||||
|
Calculation and analysis tools |
X |
X |
X |
|||||||
|
APIs |
X |
X |
X |
X |
X |
|||||
|
Database management tools |
X |
X |
X |
X |
X |
X |
||||
|
Testing and validation tools |
X |
X |
X |
|||||||
|
Documentation |
X |
X |
X |
X |
X |
|||||
|
Reproducibility and uncertainty quantification |
X |
X |
X |
X |
X |
|||||
|
Versioning and maintenance |
X |
X |
X |
X |
X |
|||||
|
Process/Analyze: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tool |
Publisher |
Research Organization Leader |
Researcher |
|
|
Software |
Systems resilience and adaptability |
X |
X |
|||||||
|
Source code repository |
X |
X |
X |
X |
X |
|||||
|
Security and software updates |
X |
X |
X |
|||||||
|
Standards, protocols, and interfaces |
X |
X |
X |
|||||||
|
Workflow and Middleware |
LIMS |
X |
||||||||
|
Laboratory notebook |
X |
X |
||||||||
|
Tools for automated metadata capture |
X |
X |
X |
X |
X |
|||||
|
Anomaly detection and correction tools |
X |
X |
X |
X |
||||||
|
Collaboration tools |
X |
X |
X |
X |
X |
|||||
|
Decisions regarding the need for additional data |
X |
X |
X |
|||||||
|
Process monitoring and evaluation |
X |
X |
||||||||
|
Containerization |
X |
|||||||||
|
Reusable workflow component |
X |
X |
X |
|||||||
|
Microservices |
||||||||||
|
Distributed workflow across sites |
X |
X |
||||||||
|
Comprehensive report generation |
X |
|||||||||
|
Hardware |
Compute requirements |
X |
X |
X |
||||||
|
Storage requirements |
X |
X |
X |
X |
||||||
|
Network requirements |
X |
|||||||||
|
Accelerator requirements |
||||||||||
|
Share/Use/Reuse: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Publishing |
Repository |
X |
X |
X |
X |
X |
X |
X |
X |
|
|
Data paper |
X |
X |
X |
X |
X |
X |
||||
|
Software |
X |
X |
X |
X |
X |
X |
||||
|
Updates to datasets and new software versions |
X |
X |
X |
X |
X |
X |
||||
|
Data linking |
X |
X |
X |
X |
X |
|||||
|
Persistent identifier |
X |
X |
X |
X |
X |
X |
||||
|
Metadata |
X |
X |
X |
X |
X |
X |
||||
|
Integrity of data |
X |
X |
X |
|||||||
|
Quality measures and assessment vis-à-vis fit for purpose |
X |
X |
X |
X |
||||||
|
Peer review of datasets and metadata |
X |
X |
X |
X |
||||||
|
Reference data/digital objects in journal articles |
X |
X |
X |
X |
||||||
|
Curation |
X |
X |
X |
X |
X |
|||||
|
Publisher agreements and policies |
X |
X |
X |
X |
X |
|||||
|
Incentives for data publishing |
X |
X |
X |
X |
X |
|||||
|
Mitigation of disincentives for data publishing |
X |
X |
X |
X |
X |
|||||
|
Modes of Dissemination |
Traditional journal article |
X |
X |
X |
X |
X |
X |
|||
|
Supplementary material |
X |
X |
X |
X |
X |
X |
||||
|
On request |
X |
X |
X |
X |
X |
|||||
|
Data landing page |
X |
X |
X |
X |
||||||
|
Workflow |
X |
X |
X |
|||||||
|
Mainstream media |
X |
|||||||||
|
Social media |
X |
X |
||||||||
|
Share/Use/Reuse: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Attribution |
Citation metrics |
X |
X |
X |
X |
X |
X |
|||
|
Citation impact |
X |
X |
X |
X |
X |
X |
X |
|||
|
Dataset citation |
X |
X |
X |
X |
X |
X |
X |
|||
|
Provenance |
X |
X |
X |
X |
||||||
|
Author identity management |
X |
X |
X |
X |
X |
X |
||||
|
Use of persistent identifiers |
X |
X |
X |
X |
X |
X |
X |
|||
|
Versioning |
X |
X |
X |
X |
||||||
|
Modes of Sharing |
Standardized formats |
X |
X |
X |
X |
X |
X |
X |
||
|
Interoperability tools |
X |
X |
X |
X |
X |
X |
||||
|
Discovery platforms |
X |
X |
X |
X |
X |
|||||
|
Catalogs |
X |
X |
X |
|||||||
|
Registries of repositories |
X |
X |
X |
X |
||||||
|
Access |
Internal access |
X |
X |
X |
X |
X |
X |
|||
|
External access |
X |
X |
X |
X |
X |
X |
||||
|
Programmatic access |
X |
X |
X |
X |
X |
X |
||||
|
Virtual and physical enclaves |
X |
X |
||||||||
|
Access vs. visiting |
X |
X |
X |
|||||||
|
Availability statement |
X |
X |
X |
|||||||
|
Mitigation of barriers and economic constraints |
X |
X |
X |
X |
||||||
|
Legal and Licenses |
Ownership |
X |
X |
X |
X |
X |
||||
|
Encouragement and support for sharing, use, and reuse |
X |
X |
X |
X |
X |
|||||
|
Indigenous data rights |
X |
X |
X |
X |
||||||
|
Intellectual property rights/restrictions |
X |
X |
X |
X |
X |
|||||
|
Share/Use/Reuse: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Legal and Licenses |
Usage agreements/terms/licenses and required permissions |
X |
X |
X |
X |
X |
X |
X |
||
|
Sharing agreements and licensing |
X |
X |
X |
X |
X |
X |
||||
|
Service-level agreements |
X |
X |
X |
X |
||||||
|
Terms of service |
X |
X |
X |
|||||||
|
Standardized, machine-actionable license documents |
X |
X |
X |
|||||||
|
Citation requirements |
X |
X |
X |
X |
X |
|||||
|
Levels of Protection |
Unclassified but sensitive information |
X |
X |
X |
X |
|||||
|
Security classification |
X |
X |
X |
X |
||||||
|
Protection of limited data/secure platforms/enclaves |
X |
X |
X |
|||||||
|
Constraints and restrictions on data use and sharing |
X |
X |
X |
|||||||
|
Anonymization |
X |
X |
X |
|||||||
|
Architectures for Application, Use, and Reuse |
Extensibility across communities, including machine-based interactions |
X |
X |
X |
||||||
|
Capture of insights from ML and use of these to improve datasets for future AI applications |
X |
X |
X |
|||||||
|
Capture of data performance characteristics |
X |
X |
X |
X |
||||||
|
Location of data |
X |
X |
X |
X |
X |
X |
||||
|
Migration strategies concerning data loss |
X |
X |
X |
|||||||
|
Economic impact of reuse |
X |
X |
||||||||
|
Preserve/Discard: Topic |
Subtopic |
AI Expert |
Budget/Cost Expert |
Curator |
Data/IT Leader |
Provider of Data Tools |
Publisher |
Research Organization Leader |
Researcher |
|
|
Criteria for Preservation |
Use |
X |
X |
X |
X |
|||||
|
Impact |
X |
X |
X |
|||||||
|
Value |
X |
X |
X |
|||||||
|
Uniqueness |
X |
X |
X |
|||||||
|
Cost |
X |
X |
X |
|||||||
|
Provenance |
X |
X |
||||||||
|
Legal and regulatory |
X |
X |
||||||||
|
Sustainability |
Longevity and support |
X |
X |
|||||||
|
Funding models |
X |
X |
X |
|||||||
|
Business models |
X |
X |
X |
|||||||
|
Storage and Preservation |
Methods to store and preserve data |
X |
||||||||
|
File integrity |
X |
|||||||||
|
Ability to do advanced searches |
X |
|||||||||
|
Backup and recovery |
X |
|||||||||
|
Moving Data from One Service to Another Across Organizations |
Roles and responsibilities |
X |
||||||||
|
Registry maintenance and curation |
X |
X |
||||||||
|
Disciplinary archives |
X |
|||||||||
|
Retention and Disposition Schedules |
Technical decisions |
X |
||||||||
|
Administrative/policy decisions |
X |
X |
||||||||
|
Deaccessioning/end-of-life |
X |
|||||||||
|
Legal documents |
X |
|||||||||
|
End-of-life special considerations |
X |
|||||||||
|
Recognition of removed data |
X |
|||||||||
6 Conclusions and Ongoing Work
Version 2.0 of the NIST RDaF has been developed through extensive stakeholder engagement via a total of 17 workshops. Carefully crafted methodologies were used in the development process, which took place over nearly two years. The RDaF is based on a lifecycle model with six stages, each having a comprehensive list of defined topics and subtopics, as well as informative references for most of the subtopics. Version 2.0 contains full descriptions of 14 overarching themes and eight sample profiles detailing the relevant subtopics for eight common job roles/functions in research data management (RDM) and in conduct of research data projects. V2.0 also contains a list of many research data management organizations, with a link to the homepage for each organization. In addition to these features and resources, a tool has been produced that enables the creation of customized profiles. Finally, a web application has been developed and released that presents an interface to all content in this RDaF V2.0 document in an interactive environment and provides new functionality such as linkages of subtopics to corresponding informative references. The link to this web application is available on the RDaF homepage. The paragraphs below describe ongoing work in various areas.
The RDaF V2.0 can be tailored and customized to fit the needs of a variety of data management professionals and organizations. The content of the RDaF is already being implemented and used in various ways. Organizations have used the topics and subtopics in V1.0 to create “scorecards” of subtopics that indicate the current state of their RDM and are using V2.0 as a guide to create implementation plans for improving RDM and for creating profiles. The RDaF could potentially be used as a basis for a data management education curriculum. NIST welcomes and encourages additional creative uses of the RDaF by the community.
The research data ecosystem is evolving rapidly and NIST intends to release updates of the RDaF on a regular basis (subject to availability of resources). Additionally, NIST will assist the research data community, including organizations and individuals engaged in or interested in using the framework, to assess and improve their RDM. NIST will also seek partnerships with organizations having similar aspirations, such as the Australian Research Data Commons, who recently released their “Research Data Management Framework for Institutions”[262] and the Research Data Alliance’s new working group, the “RDA-OfR Mapping the Landscape of Digital Research Tools [266].” Finally, NIST is following the development of frameworks in other areas, such as the Sendai Framework for Disaster Risk Reduction [267]. NIST encourages organizations and individuals seeking assistance in using the RDaF or considering the development of value-added tools based on the RDaF to contact the team at [email protected].
Given the complexity of the framework, the RDaF team is working on various tools to improve accessibility and applicability of the framework. The RDaF V2.0 interactive web application described in section 2.3 has an intuitive design such that users can easily navigate all components in the V2.0 document and view relationships among these components. New features of this web application such as graphical navigation, a user feedback form, and a guided profile-maker are under development.
Interactive, web-based knowledge graphs are being developed to visually demonstrate the interconnected nature of the many subjects and tasks in RDM [268]. The knowledge graphs will allow exploration of the relationships between, e.g., topics, subtopics, and job functions (profiles) within the research data ecosystem. Such interactive knowledge graphs enable individuals and organizations to approach RDM from a variety of perspectives and starting points. A user will be able to select any component of the framework, determine the other components to which the starting component is linked, and navigate through the diagram in an intuitive manner. For example, a researcher interested in metadata may start at one subtopic, then move to the overarching themes related to that subtopic. Next, that individual may review the sample researcher profile to determine other subtopics associated with metadata. Parsing through these subtopics, the researcher may encounter, for example, the data privacy subtopic, for which more knowledge is desired. To obtain this knowledge, the researcher then navigates to the informative references for that subtopic.
Due to the complex nature of RDM, the RDaF was designed to be comprehensive and broadly applicable. As a multifaceted tool, it can be used to address various aspects of RDM for organizations and individuals, e.g., assessment of the state of RDM using the RDaF lifecycle stages/topics/subtopics, development of strategies to improve RDM infrastructure, policies, and practices, and identification of RDM tasks and responsibilities for specific job roles or functions. Organizations and individuals seeking to use the RDaF for these and other purposes may need assistance. To this end, NIST intends to develop and publish a best practice guide for various use scenarios in collaboration with different stakeholder groups. Such a guide will focus on use of the RDaF for general topics, such as: assessment of existing RDM policies and practices; determination of goals for RDM; creation of step-by-step plans for reaching RDM goals; generation of curricula for continuing education and other training materials; and creation of job descriptions with individualized workplans.
The various workshops held to further develop the RDaF resulted in many transcripts and notes. The methodology section 2 described a manual, human-driven method of incorporating that feedback to generate V2.0. As a supplement and an experimental exercise, the RDaF team is also exploring natural language processing as a method to extract insight and draw conclusions via machine learning. These findings will be compared with the results of the manual process and may be incorporated in future versions of the RDaF.
[1] Office of the Federal Register NA and RA (2014) 2 CFR § 200.315 - Intangible property. govinfo.gov. Available at https://www.govinfo.gov/app/details/CFR-2014-title2-vol1/CFR-2014-title2-vol1-sec200-315
[2] Hanisch RJ,, Kaiser DL, Carroll BC, (2021) Research Data Framework (RDaF) :: motivation, development, and a preliminary framework core. (National Institute of Standards and Technology (U.S.), Gaithersburg, MD), NIST SP 1500-18. https://doi.org/10.6028/NIST.SP.1500-18
[3] Data Asset NIST Computer Security Resource Center Glossary. Available at https://csrc.nist.gov/glossary/term/data_asset
[4] Hanisch RJ, Kaiser DL, Yuan A, Medina-Smith A, Carroll BC, Campo EM, (2023) NIST Research Data Framework (RDaF): version 1.5. (National Institute of Standards and Technology (U.S.), Gaithersburg, MD), NIST SP 1500-18r1. https://doi.org/10.6028/NIST.SP.1500-18r1
[5] Research Data Management Terminology CODATA, The Committee on Data for Science and Technology. Available at https://codata.org/initiatives/data-science-and-stewardship/rdm-terminology-wg/rdm-terminology/
[6] Techopedia: Educating IT Professionals To Make Smarter Decisions - Techopedia Available at https://www.techopedia.com/
[7] What is the difference between mission, vision and values statements? (2023) SHRM. Available at https://www.shrm.org/resourcesandtools/tools-and-samples/hr-qa/pages/mission-vision-values-statements.aspx
[8] Data policy CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/data-policy
[9] Data governance CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/data-governance
[10] National Institute of Standards and Technology (2018) Framework for Improving Critical Infrastructure Cybersecurity, Version 1.1. (National Institute of Standards and Technology, Gaithersburg, MD), NIST CSWP 04162018. Available at https://doi.org/10.6028/NIST.CSWP.04162018
[11] Data management CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/data-management
[12] What are organizational values? Workplace from Meta. Available at https://www.workplace.com/blog/organizational-values
[13] Verlinden N, (2021) Organizational Values: Definition, Purpose & Lots of Examples. AIHR. Available at https://www.aihr.com/blog/organizational-values/
[14] Briggs LL, (2011) Q&A: Solid Value Proposition a Key to MDM Success. Transforming Data with Intelligence. Available at https://tdwi.org/articles/2011/02/16/value-proposition-mdm-success.aspx
[15] NOAA Administrative Order 212-15 (National Oceanic and Atmospheric Administration), 212–15, p 4. Available at https://www.noaa.gov/sites/default/files/legacy/document/2020/Mar/212-15.pdf
[16] What is Data Privacy SNIA. Available at https://secure.livechatinc.com/
[17] Data ethics Cognizant Glossary. Available at https://www.cognizant.com/us/en/glossary/data-ethics
[18] Kengadaran S, (2019) Ethics for Data Projects. Siddarth Kengadaran. Available at https://siddarth.design/ethics-for-data-projects-5af0af333e71
[19] Bhandari P, (2022) Ethical Considerations in Research | Types & Examples. Scribbr. Available at https://www.scribbr.com/methodology/research-ethics/
[20] What is Data Security? Data Security Definition and Overview IBM. Available at https://www.ibm.com/topics/data-security
[21] Molch K., Cosac R., (2020) Long Term Preservation of Earth Observation Space Data: Glossary of Acronyms and Terms. Available at https://ceos.org/document_management/Working_Groups/WGISS/Interest_Groups/Data_Stewardship/White_Papers/EO-DataStewardshipGlossary.pdf
[22] Karen Scarfone How to Perform a Data Risk Assessment, Step by Step. Tech Target. Available at https://www.techtarget.com/searchsecurity/tip/How-to-perform-a-data-risk-assessment-step-by-step
[23] What is Data Risk Management? Why You Should Care? (2022) The ECM Consultant. Available at https://theecmconsultant.com/data-risk-management/
[24] Data Sharing Agreements US Geological Survey. Available at https://www.usgs.gov/data-management/data-sharing-agreements
[25] Data License Agreement (2021) Dimewiki. Available at https://dimewiki.worldbank.org/Data_License_Agreement
[26] Intellectual property (2023) Wikipedia. Available at https://en.wikipedia.org/w/index.php?title=Intellectual_property&oldid=1171678348
[27] Foreground Intellectual Property: Everything You Need to Know UpCounsel. Available at https://www.upcounsel.com/foreground-intellectual-property
[28] Aitken M, Toreini E, Carmichael P, Coopamootoo K, Elliott K, van Moorsel A (2020) Establishing a social licence for Financial Technology: Reflections on the role of the private sector in pursuing ethical data practices. Big Data & Society 7(1):2053951720908892. 10.1177/2053951720908892
[29] Sariyar M, Schluender I, Smee C, Suhr S (2015) Sharing and Reuse of Sensitive Data and Samples: Supporting Researchers in Identifying Ethical and Legal Requirements. Biopreservation and Biobanking 13(4):263–270. 10.1089/bio.2015.0014
[30] Southekal P, (2022) Data Culture: What It Is And How To Make It Work. Forbes. Available at https://www.forbes.com/sites/forbestechcouncil/2022/06/27/data-culture-what-it-is-and-how-to-make-it-work/
[31] Scientific Integrity and Research Misconduct Available at https://www.usda.gov/our-agency/staff-offices/office-chief-scientist-ocs/scientific-integrity-and-research-misconduct
[32] What Is Data Integrity and Why Does It Matter? (2021) Business Insights Blog. Available at https://online.hbs.edu/blog/post/what-is-data-integrity
[33] Wilkinson MD, Dumontier M, Aalbersberg IjJ, Appleton G, Axton M, Baak A, Blomberg N, Boiten J-W, da Silva Santos LB, Bourne PE, Bouwman J, Brookes AJ, Clark T, Crosas M, Dillo I, Dumon O, Edmunds S, Evelo CT, Finkers R, Gonzalez-Beltran A, Gray AJG, Groth P, Goble C, Grethe JS, Heringa J, ’t Hoen PAC, Hooft R, Kuhn T, Kok R, Kok J, Lusher SJ, Martone ME, Mons A, Packer AL, Persson B, Rocca-Serra P, Roos M, van Schaik R, Sansone S-A, Schultes E, Sengstag T, Slater T, Strawn G, Swertz MA, Thompson M, van der Lei J, van Mulligen E, Velterop J, Waagmeester A, Wittenburg P, Wolstencroft K, Zhao J, Mons B (2016) The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data 3(1):160018. 10.1038/sdata.2016.18
[34] CARE Principles of Indigenous Data Governance (2023) Global Indigenous Data Alliance. Available at https://www.gida-global.org/care
[35] Stakeholder CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/stakeholder
[36] Numans W, Van Regenmortel T, Schalk R (2019) Partnership Research: A Pathway to Realize Multistakeholder Participation. International Journal of Qualitative Methods 18:1609406919884149. 10.1177/1609406919884149
[37] Domain knowledge (2023) Wikipedia. Available at https://en.wikipedia.org/w/index.php?title=Domain_knowledge&oldid=1136257348
[38] inclusivity (2023) Cambridge Dictionary online. Available at https://dictionary.cambridge.org/us/dictionary/english/inclusivity
[39] Data Services (2015) Techopedia. Available at https://www.techopedia.com/definition/1005/data-services
[40] Insights CISA,: Chain of Custody and Critical Infrastructure Systems Available at https://www.cisa.gov/sites/default/files/publications/cisa-insights_chain-of-custody-and-ci-systems_508.pdf
[41] Provenance CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/provenance
[42] Perreault G, Kim P, Foster W (2011) Finding Your Funding Model. Stanford Social Innovation Review 9:3741. 10.48558/QPQR-QT49
[43] Cost–benefit analysis (2023) Wikipedia. Available at https://en.wikipedia.org/w/index.php?title=Cost%E2%80%93benefit_analysis&oldid=1136963825
[44] DCC (2013) Checklist for a Data Management Plan. v.4.0. Available at https://www.dcc.ac.uk/sites/default/files/documents/resource/DMP/DMP_Checklist_2013.pdf
[45] Jones S, Pergl R, Hooft R, Miksa T, Samors R, Ungvari J, Davis RI, Lee T (2020) Data Management Planning: How Requirements and Solutions are Beginning to Converge. Data Intelligence 2(1–2):208–219. 10.1162/dint_a_00043
[46] Machine readable CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/machine-readable
[47] What is Data Organization? - Importance & Tips Sisense. Available at https://www.sisense.com/glossary/data-organization/
[48] Mcleod Saul, (2022) Qualitative vs Quantitative Research: Methods & Data Analysis. Simply Psychology. Available at https://simplypsychology.org/qualitative-quantitative.html
[49] Observation Definition & Meaning Merriam-Webster. Available at https://www.merriam-webster.com/dictionary/observation
[50] Survey (human research) (2023) Wikipedia. Available at https://en.wikipedia.org/w/index.php?title=Survey_(human_research)&oldid=1135741584
[51] What is Research Software? IGI Global. Available at https://www.igi-global.com/dictionary/knowledge-visualization-for-research-design/69111
[52] Modeling in Scientific Research Visionlearning Process of Science. Available at https://www.visionlearning.com/en/library/Process-of-Science/49/Modeling-in-Scientific-Research/153
[53] Documented data CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/documented-data
[54] Bechhofer S, De Roure D, Gamble M, Goble C, Buchan I (2010) Research Objects: Towards Exchange and Reuse of Digital Knowledge. Nature Precedings:1–1. 10.1038/npre.2010.4626.1
[55] Dobreski B, Park J, Leathers A, Qin J, (2020) Remodeling Archival Metadata Descriptions for Linked Archives. International Conference on Dublin Core and Metadata Applications, pp 1–11. Available at https://dcpapers.dublincore.org/pubs/article/view/4223
[56] Metadata Object Description Schema: MODS (2022) Library of Congress. Available at https://www.loc.gov/standards/mods/
[57] What is a Data Workflow? Use Cases & How to Get Started (2023) Cflow. Available at https://www.cflowapps.com/data-workflow/
[58] Model NIST Computer Security Resource Center Glossary. Available at https://csrc.nist.gov/glossary/term/model
[59] Laboratory Information Management System (LIMS) (2018) Techopedia. Available at https://www.techopedia.com/definition/8085/laboratory-information-management-system-lims
[60] Architecture CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/architecture
[61] Research Data Architectures in Research Institutions IG (2017) RDA. Available at https://www.rd-alliance.org/groups/research-data-architectures-research-institutions-ig
[62] Management Configuration, (2012) Techopedia. Available at https://www.techopedia.com/definition/24822/configuration-controlconfiguration-management-cm
[63] Interoperability CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/interoperability
[64] Stocker M, Darroch L, Krahl R, Habermann T, Devaraju A, Schwardmann U, D’Onofrio C, Häggström I (2020) Persistent Identification of Instruments. Data Science Journal 19(1):18. 10.5334/dsj-2020-018
[65] Data standards Data.gov. Available at https://resources.data.gov/standards/concepts/
[66] Data Quality (2022) Techopedia. Available at https://www.techopedia.com/definition/14653/data-quality
[67] Standard CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/standard
[68] Sansone S-A, (2016) NIH BD2K workshop report: “Frameworks for Community-based Standards Efforts”. Available at https://doi.org/10.6084/m9.figshare.3795816.v2
[69] Ball A, Duke M, (2015) How to Track the Impact of Research Data with Metrics. Available at https://www.dcc.ac.uk/guidance/how-guides/track-data-impact-metrics
[70] Alpi KM, Akers KG (2021) CRediT for authors of articles published in the Journal of the Medical Library Association. Journal of the Medical Library Association 109(3):362–364. 10.5195/jmla.2021.1294
[71] Regulatory compliance (2023) Wikipedia. Available at https://en.wikipedia.org/w/index.php?title=Regulatory_compliance&oldid=1147347472
[72] PII NIST Computer Security Resource Center Glossary. Available at https://csrc.nist.gov/glossary/term/pii
[73] Intellectual Property Sample Clauses, Law Insider. Available at https://www.lawinsider.com/clause/intellectual-property
[74] Responsible Conduct in Data Management Glossary Available at https://ori.hhs.gov/education/products/n_illinois_u/datamanagement/dmglossary.html#A
[75] File Text, (2016) Techopedia. Available at https://www.techopedia.com/definition/9707/text-file
[76] Simulation (2019) Techopedia. Available at https://www.techopedia.com/definition/5757/simulation
[77] Computation www.dictionary.com. Available at https://www.dictionary.com/browse/computation
[78] Code Source, (2017) Techopedia. Available at https://www.techopedia.com/definition/547/source-code
[79] Transaction Definition & Meaning Merriam-Webster. Available at https://www.merriam-webster.com/dictionary/transaction
[80] Social media (2023) Wikipedia. Available at https://en.wikipedia.org/w/index.php?title=Social_media&oldid=1147905665
[81] Facility User, (2014) Department of Energy OSTI. Available at https://science.osti.gov/User-Facilities/Policies-and-Processes/Definition
[82] Koch R, (2022) Human Annotated Data - All You Need to Know About It. clickworker.com. Available at https://www.clickworker.com/customer-blog/human-annotated-data/
[83] Hillemann B, (2023) Experimental Data. Macalester University Dewitt Wallace Library LibGuides. Available at https://libguides.macalester.edu/c.php?g=527786&p=3608643
[84] Reproducible research CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/reproducible-research
[85] International vocabulary of metrology – Basic and general concepts and associated terms (VIM), 3rd Edition (2012) Available at https://www.bipm.org/en/search?p_p_id=search_portlet&p_p_lifecycle=2&p_p_state=normal&p_p_mode=view&p_p_resource_id=%2Fdownload%2Fpublication&p_p_cacheability=cacheLevelPage&_search_portlet_dlFileId=41373499&p_p_lifecycle=1&_search_portlet_javax.portlet.action=search&_search_portlet_formDate=1670328688739&_search_portlet_query=VIM&_search_portlet_source=BIPM
[86] Hardware (2020) Techopedia. Available at https://www.techopedia.com/definition/2210/hardware-hw
[87] System Requirements (2015) Techopedia. Available at https://www.techopedia.com/definition/4371/system-requirements
[88] Version control CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/version-control
[89] Versioning Document, (2014) Techopedia. Available at https://www.techopedia.com/definition/30702/document-versioning
[90] Thacker B.H., Doebling S.W., Hemez F.M., Anderson M.C., Pepin J.E., Rodriguez E.A., (2004) Concepts of Model Verification and Validation., LA-14167, 835920, p LA-14167, 835920. Available at https://doi.org/10.2172/835920
[91] Metadata CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/metadata
[92] Paradata (2022) Wikipedia. Available at https://en.wikipedia.org/w/index.php?title=Paradata&oldid=1078821391
[93] Alan F., Karr (2020) Metadata and Paradata: Information Collection and Potential Initiatives. National Institute of Statistical Sciences. Available at https://www.niss.org/research/metadata-and-paradata-information-collection-and-potential-initiatives
[94] Repository CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/repository
[95] Data integrity CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/data-integrity
[96] Critical Evaluation Criteria (2021) NIST. Available at https://www.nist.gov/srd/critical-evaluation-criteria
[97] Saha CN, Bhattacharya S (2011) Intellectual property rights: An overview and implications in pharmaceutical industry. Journal of Advanced Pharmaceutical Technology & Research 2(2):88. 10.4103/2231-4040.82952
[98] FAIR Digital Objects Available at https://fairdo.org/1316-2/
[99] Smart API, | About (2022) SmartAPI. Available at https://smart-api.info/about
[100] What does data format mean? Available at https://www.definitions.net/definition/data+format
[101] Structure File, MIT Communication Lab. Available at https://mitcommlab.mit.edu/broad/commkit/file-structure/
[102] file structure SAA Dictionary of Archives Terminology. Available at https://dictionary.archivists.org/entry/file-structure.html
[103] Bolam M, Guides: Metadata & Discovery @ Pitt: Metadata Standards. Available at https://pitt.libguides.com/metadatadiscovery/metadata-standards
[104] Metadata Standards Catalog Available at https://rdamsc.bath.ac.uk/
[105] What is an Ontology? Available at https://www.oxfordsemantic.tech/fundamentals/what-is-an-ontology
[106] Sansone S-A, Rocca-Serra P, (2016) Review: Interoperability standards. Available at https://doi.org/10.6084/m9.figshare.4055496.v1
[107] Open-Source Software (2016) Techopedia. Available at https://www.techopedia.com/definition/5602/open-source-software-oss
[108] Proprietary Software (2017) Techopedia. Available at https://www.techopedia.com/definition/4333/proprietary-software
[109] Electronic Laboratory Notebook (ELN) NNLM. Available at https://www.nnlm.gov/guides/data-glossary/electronic-laboratory-notebook-eln
[110] Srivastav AK, (2019) Graphs vs Charts. WallStreetMojo. Available at https://www.wallstreetmojo.com/graphs-vs-charts/
[111] Instrument output data CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/instrument-output-data
[112] Dynamic data CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/dynamic-data
[113] Static Data (2018) Techopedia. Available at https://www.techopedia.com/definition/31590/static-data
[114] Dataset CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/dataset
[115] Banks J, ed. (2001) Discrete-event system simulation (Prentice Hall, Upper Saddle River, NJ), 3rd ed. Available at https://worldcat.org/title/43945281
[116] Structured data CODATA, The Committee on Data for Science and Technology. Available at https://terms.codata.org/rdmt/structured-data
[117] Data cleaning CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/data-cleaning
118 ISO 25237:2017Health informatics — Pseudonymization, ISO 25237:2017. Available at https://www.iso.org/standard/63553.html
[119] Data Preprocessing (2021) Techopedia. Available at https://www.techopedia.com/definition/14650/data-preprocessing
[120] Schouten RM, Lugtig P, Vink G (2018) Generating missing values for simulation purposes: a multivariate amputation procedure. Journal of Statistical Computation and Simulation 88(15):2909–2930. 10.1080/00949655.2018.1491577
[121] Badr W, (2019) 6 Different Ways to Compensate for Missing Data (Data Imputation with examples). Towards Data Science. Available at https://towardsdatascience.com/6-different-ways-to-compensate-for-missing-values-data-imputation-with-examples-6022d9ca0779
[122] King T, (2018) The Definitive Data Management Glossary. Solutions Review. Available at https://solutionsreview.com/data-management/the-definitive-data-management-glossary/
[123] Schwer LE (2007) An overview of the PTC 60/V&V 10: guide for verification and validation in computational solid mechanics. Engineering with Computers 23(4):245–252. 10.1007/s00366-007-0072-z
[124] Data Curation NNLM. Available at https://www.nnlm.gov/guides/data-glossary/data-curation
[125] Lu M, Zhao Q, Zhang J, Pohl KM, Fei-Fei L, Niebles JC, Adeli E, (2021) Metadata Normalization. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp 10912–10922. 10.1109/CVPR46437.2021.01077
[126] Manual Data Processing: The Secrets of Automation (2021) Solvexia.com. Available at https://www.solvexia.com/blog/manual-data-processing-the-secrets-of-automation
[127] Exploratory Data Analysis (2017) Techopedia. Available at https://www.techopedia.com/definition/32962/exploratory-data-analysis-eda
[128] Cote Catherine, (2021) What Is Descriptive Analytics? 5 Examples. Business Insights Blog. Available at https://online.hbs.edu/blog/post/descriptive-analytics
[129] Cote Catherine, (2021) What Is Diagnostic Analytics? 4 Examples. Business Insights Blog. Available at https://online.hbs.edu/blog/post/diagnostic-analytics
[130] Parker Susan, Gwen Fariss Newman What is evaluation? Available at https://www.eval.org/Portals/0/What%20is%20evaluation%20Document.pdf
[131] Cote Catherine, (2021) What Is Predictive Analytics? 5 Examples. Business Insights Blog. Available at https://online.hbs.edu/blog/post/predictive-analytics
[132] Cote Catherine, (2021) What Is Prescriptive Analytics? 6 Examples. Business Insights Blog. Available at https://online.hbs.edu/blog/post/prescriptive-analytics
[133] Framework Rainbow, Rainbow Framework. Available at https://www.betterevaluation.org/frameworks-guides/rainbow-framework
[134] Correlation Positive,: What It Is, How to Measure It, Examples (2022) Investopedia. Available at https://www.investopedia.com/terms/p/positive-correlation.asp
[135] Correlation Negative,: How it Works, Examples And FAQ Investopedia. Available at https://www.investopedia.com/terms/n/negative-correlation.asp
[136] Analysis Statistical, (2022) WallStreetMojo. Available at https://www.wallstreetmojo.com/statistical-analysis/
[137] statistical data analysis WhatIs.com. Available at https://www.techtarget.com/whatis/search/query?q=statistical+data+analysis
[138] Things Autonomous, (2019) Techopedia. Available at https://www.techopedia.com/definition/33723/autonomous-things
[139] Simulation vs. Visualization - what’s the difference? (2017) Visual Components. Available at https://www.visualcomponents.com/resources/blog/simulation-vs-visualization-difference/
[140] Machine Learning Techopedia. Available at https://www.techopedia.com/topic/318/machine-learning
[141] Artificial Intelligence Techopedia. Available at https://www.techopedia.com/topic/87/artificial-intelligence
[142] Pedamkar Priya, (2019) Iterative Model. EDUCBA. Available at https://www.educba.com/iterative-model/
[143] Integrated Development Environment (2017) Techopedia. Available at https://www.techopedia.com/definition/26860/integrated-development-environment-ide
[144] Cofield M, (2022) Metadata Basics: Key Concepts. University of Texas Libraries. Available at https://guides.lib.utexas.edu/metadata-basics/key-concepts
[145] Dennis AL, (2022) The Value of Metadata Governance. DATAVERSITY. Available at https://www.dataversity.net/the-value-metadata-governance/
[146] Gilliland AJ, (2016) Setting the Stage. Introduction to Metadata Available at http://www.getty.edu/publications/intrometadata
[147] Data linkage CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/data-linkage
[148] Persistent identifier CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/persistent-identifier
[149] What are Persistent Identifiers (2020) CERN. Available at https://sis.web.cern.ch/submit-and-publish/persistent-identifiers/what-are-pids
[150] Authoritative copies Docusign Developer. Available at https://developers.docusign.com/docs/esign-rest-api/esign101/concepts/documents/authoritative-copies/
[151] Glossary of data management terms | Research Data Management Service Group (2022) Cornell University. Available at https://data.research.cornell.edu/content/glossary
[152] Jeffreys A, (2018) Database subsetting. Redgate. Available at https://www.red-gate.com/blog/database-devops/database-subsetting-wed-love-hear
[153] Timestamp (2016) Techopedia. Available at https://www.techopedia.com/definition/16285/timestamp
[154] CRediT (2011) CRediT. Available at https://credit.niso.org/
[155] Commercial Software (2014) Techopedia. Available at https://www.techopedia.com/definition/4245/commercial-software
[156] What is Custom Software? Available at https://www.computerhope.com/jargon/c/customso.htm
[157] software WhatIs.com. Available at https://www.techtarget.com/whatis/search/query?q=software
[158] Statistics (2023) Wikipedia. Available at https://en.wikipedia.org/w/index.php?title=Statistics&oldid=1148101750
[159] Application Programming Interface (2022) Techopedia. Available at https://www.techopedia.com/definition/24407/application-programming-interface-api
[160] Data Management Software (2013) Techopedia. Available at https://www.techopedia.com/definition/11363/data-management-software-dms
[161] Data Validation (2017) Techopedia. Available at https://www.techopedia.com/definition/10283/data-validation
[162] What is Software Documentation? Definition, Types and Examples Tech Target - Software Quality. Available at https://www.techtarget.com/searchsoftwarequality/definition/documentation
[163] resilience NIST Computer Security Resource Center Glossary. Available at https://csrc.nist.gov/glossary/term/resilience
[164] Subramanian N, Chung L, (2001) Metrics for Software Adaptability. Available at https://personal.utdallas.edu/~chung/ftp/sqm.pdf
[165] What is a Software Repository? (2021) Full Scale. Available at https://fullscale.io/blog/software-repository/
[166] Data Management Glossary National Agriculture Library. Available at https://www.nal.usda.gov/data/data-management-glossary#W3clib
[167] Update NIST Computer Security Resource Center Glossary. Available at https://csrc.nist.gov/glossary/term/update
[168] Resources.data.gov: a Repository of Federal Enterprise Data Resources Data management & governance resources. Available at https://resources.data.gov/categories/data-management-governance/
[169] Protocol (2020) Techopedia. Available at https://www.techopedia.com/definition/4528/protocol
[170] What is an Interface? (2020) Computer Hope. Available at https://www.computerhope.com/jargon/i/interfac.htm
[171] Ryan P Webinar on Keeping a Lab Notebook - Basic Principles and Best Practices. Available at https://www.training.nih.gov/assets/Lab_Notebook_508_(new).pdf
[172] Detection Anomaly, (2014) Techopedia. Available at https://www.techopedia.com/definition/30297/anomaly-detection
[173] Flow Work, (2016) Techopedia. Available at https://www.techopedia.com/definition/10072/work-flow
[174] Middleware (2017) Techopedia. Available at https://www.techopedia.com/definition/450/middleware
[175] Middleware CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/middleware
[176] What is Monitoring - Types of Monitoring, Process Monitoring, Validation, Tracking, Performance Monitoring and Evaluation Studies. Available at http://www.mnestudies.com/monitoring/what-monitoring
[177] Containerization (computing) (2023) Wikipedia. Available at https://en.wikipedia.org/w/index.php?title=Containerization_(computing)&oldid=1148088666
[178] Library (Reusable components) (2018) UiPath Community Forum. Available at https://forum.uipath.com/t/featureblog-18-3-library-reusable-components/62746
[179] Microservices (2021) Techopedia. Available at https://www.techopedia.com/definition/32503/microservices
[180] Workflow Management System NIST Computer Security Resource Center Glossary. Available at https://csrc.nist.gov/glossary/term/workflow_management_system
[181] Compute (2016) Techopedia. Available at https://www.techopedia.com/definition/6580/compute
[182] Million Instructions per Second (MIPS) Gartner Information Technology Glossary. Available at https://www.gartner.com/en/information-technology/glossary/mips-million-instructions-per-second
[183] Storage (2022) Techopedia. Available at https://www.techopedia.com/definition/1115/storage
[184] Madden S, (2019) Network Speed vs. Bandwidth? Interconnections - The Equinix Blog. Available at https://blog.equinix.com/blog/2019/05/09/network-speed-vs-bandwidth/?lang=ja
[185] What is an Accelerator? Available at https://www.computerhope.com/jargon/a/accelera.htm
[186] What Is Hardware Acceleration, and It When Should You Use,? (2021) Make Use Of. Available at https://www.makeuseof.com/what-is-hardware-acceleration/
[187] Stall Shelley, Martone Maryann E., Chandramouliswaran Ishwar, Crosas Mercè, Federer Lisa, Gautier Julian, Hahnel Mark, Larkin Jennie, Lowenberg Daniella, Pfeiffer Nicole, Sim Ida, Smith Tim, Van Gulick Ana E., Walker Erin, Wood Julie, Zaringhalam Maryam, Zigoni Alberto, (2020) Generalist Repository Comparison Chart. Available at https://doi.org/10.5281/ZENODO.3946720
[188] Data Repository Egnyte. Available at https://www.egnyte.com/guides/governance/data-repository
[189] Research data publishing Springer Nature. Available at https://www.springernature.com/gp/authors/research-data/research-data-publishing
[190] Support and information Wageningen Data Competence Center Contact form (2015) Why publish research data? Wageningen University & Research. Available at https://www.wur.nl/en/value-creation-cooperation/collaborating-with-wur-1/wdcc/research-data-management-wdcc/finishing/why-publish-research-data.htm
[191] DATA UPDATING Law Insider. Available at https://www.lawinsider.com/dictionary/data-updating
[192] What is Data Linking? TIBCO Software. Available at https://www.tibco.com/reference-center/what-is-data-linking
[193] What is Data Integrity and How Can You Maintain it? Inside Out Security Blog. Available at https://www.varonis.com/blog/data-integrity
[194] Sarfin RL, (2022) Data Quality Dimensions: How Do You Measure Up? (+ Free Scorecard). Precisely. Available at https://www.precisely.com/blog/data-quality/data-quality-dimensions-measure
[195] Research Data Guidelines Elsevier Author Tools. Available at https://www.elsevier.com/authors/tools-and-resources/research-data/data-guidelines
[196] Publishing Agreement: Definition & Sample Contract Counsel. Available at https://www.contractscounsel.com/t/us/publishing-agreement
[197] OA agreements Author Services - Taylor & Francis. Available at https://authorservices.taylorandfrancis.com/choose-open/publishing-open-access/oa-agreements/
[198] Publishing policies | Policies | Springer Nature Springer Nature. Available at https://www.springernature.com/gp/policies/publishing-policies
[199] Scholarly Publishing: Traditional and Open Access Rutgers University Libraries. Available at https://www.libraries.rutgers.edu/research-tools-and-services/copyright-guidance/copyright-academic-research-and-publication/scholarly-publishing-traditional-and-open-access
[200] Supplementary information | Nature Available at https://www.nature.com/nature/for-authors/supp-info
[201] Submit a Data Request National Resident Matching Program. Available at https://www.nrmp.org/match-data-analytics/submit-a-data-request/
[202] What is a Landing Page and Why Should You Use Them? Mailchimp. Available at https://mailchimp.com/marketing-glossary/landing-pages/
[203] mainstream media (2023) Cambridge Dictionary. Available at https://dictionary.cambridge.org/us/dictionary/english/mainstream-media
[204] Media Social, Techopedia. Available at https://www.techopedia.com/definition/4837/social-media
[205] Fisher T, LibGuides: Research Publishing & Impact: Citation Metrics. University of Otago Library. Available at https://otago.libguides.com/research_publishing_impact/citation_metrics
[206] DeGroote S Measuring Your Impact: Impact Factor, Citation Analysis, and other Metrics: Citation Analysis. UIC Libraries Research Guides. Available at https://researchguides.uic.edu/c.php?g=252299&p=1683205
[207] Sharma M, Sarin A, Gupta P, Sachdeva S, Desai AV (2014) Journal Impact Factor: Its Use, Significance and Limitations. World Journal of Nuclear Medicine 13(2):146. 10.4103/1450-1147.139151
[208] - Data Citation and Policies. Land Processes Distributed Active Archive Center (LP DAAC. US Geological Survey. Available at https://lpdaac.usgs.gov/data/data-citation-and-policies/
[209] Cite Your Data DataCite. Available at https://datacite.org/cite-your-data.html
[210] Data Citation Synthesis Group (2014) Joint Declaration of Data Citation Principles. (Force11). Available at https://doi.org/10.25490/A97F-EGYK
[211] Research Guides: Author Identity Management: ORCID Run Run Shaw Library City University of Hong Kong. Available at https://libguides.library.cityu.edu.hk/aim/orcid
[212] Content discovery platform (2023) Wikipedia. Available at https://en.wikipedia.org/w/index.php?title=Content_discovery_platform&oldid=1135084424
[213] Data Catalog (2016) Techopedia. Available at https://www.techopedia.com/definition/32034/data-catalog
[214] Registry CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/registry
[215] re3data re3data. Available at https://www.re3data.org/
[216] Materials Resource Registry NIST, National Institute of Standards and Technology. Available at https://www.nist.gov/programs-projects/nist-materials-resource-registry
[217] Data Access (2012) Techopedia. Available at https://www.techopedia.com/definition/26929/data-access
[218] Data Enclave Network of the National Library of Medicine. Available at https://www.nnlm.gov/guides/data-thesaurus/data-enclave
[219] Weise M, Kovacevic F, Popper N, Rauber A (2022) OSSDIP: Open Source Secure Data Infrastructure and Processes Supporting Data Visiting. Data Science Journal 21(1):4. 10.5334/dsj-2022-004
[220] Data Availability Statements - Research Data Policy (2022) Springer Nature. Available at https://www.springernature.com/gp/authors/research-data-policy/data-availability-statements
[221] Data Ownership (2012) Techopedia. Available at https://www.techopedia.com/definition/29059/data-ownership
[222] Property Intellectual, (2022) Techopedia. Available at https://www.techopedia.com/definition/5521/intellectual-property-ip
[223] User Agreements 101: What You Need to Know Ironclad. Available at https://ironcladapp.com/journal/contracts/user-agreements/
[224] Licensing Agreement: What Is It? 5 Elements To Include Available at https://www.contractscounsel.com/t/us/licensing-agreement
[225] Harper (Michael) (2021) The relationship between data SLAs & data products. Medium. Available at https://towardsdatascience.com/the-relationship-between-data-slas-data-products-77207f876072
[226] Terms of Service (2015) Techopedia. Available at https://www.techopedia.com/definition/9746/terms-of-service-tos
[227] 12 FAM 540 SENSITIVE BUT UNCLASSIFIED INFORMATION (SBU). Foreign Affairs Manual (U.S. Department of State). Available at https://fam.state.gov/fam/12fam/12fam0540.html
[228] De-Identification Guidelines (2018) Safety and Risk Services - University of Oregon. Available at https://safety.uoregon.edu/de-identification-guidelines
[229] Controlled Unclassified Information (CUI) (2016) National Archives. Available at https://www.archives.gov/cui
[230] Guide Classification,: Protection Levels - Information Security & Privacy Office New School - Information & Privacy Office. Available at https://ispo.newschool.edu/guidelines/protection-levels/
[231] 5 FAM 480 CLASSIFYING AND DECLASSIFYING NATIONAL SECURITY INFORMATION—EXECUTIVE ORDER 13526. Foreign Affairs Manual (U.S. Department of State). Available at https://fam.state.gov/fam/05fam/05fam0480.html
[232] Ross R, Pillitteri V, (2020) Security and Privacy Controls for Information Systems and Organizations. (National Institute of Standards and Technology, Gaithersburg, MD), SP 800-53r5. Available at https://doi.org/10.6028/NIST.SP.800-53r5
[233] 6 Must-Haves in a Data Security Platform CIO. Available at https://www.cio.com/article/407778/6-must-haves-in-a-data-security-platform.html
[234] Limited Data Sets and Data Use Agreements (2020) Available at https://www.womans.org/-/media/files/womans/research/policies/limited-data-sets-and-data-use-agreements.pdf?la=en&hash=6772539AC17E04ECE6ECAF00BDA3DB0ED8329F71
[235] Howison M, Angell M, Hicklen MS, Hastings JS (2021) Protecting Sensitive Data with Secure Data Enclaves (OSF Preprints). 10.31219/osf.io/jmd7t
[236] Data Anonymization Corporate Finance Institute. Available at https://corporatefinanceinstitute.com/resources/business-intelligence/data-anonymization/
[237] Extensibility (2021) Wikipedia. Available at https://en.wikipedia.org/w/index.php?title=Extensibility&oldid=1008862248
[238] 7 data quality best practices to improve data performance | TechTarget TechTarget Data Management. Available at https://www.techtarget.com/searchdatamanagement/tip/Data-quality-best-practices-to-improve-data-performance
[239] Metrics Digital Preservation, Center for Research Libraries: Global Resources Network. Available at https://www.crl.edu/archiving-preservation/digital-archives/metrics
[240] Definition of uniqueness | Dictionary.com www.dictionary.com. Available at https://www.dictionary.com/browse/uniqueness
[241] Data longevity PCMAG. Available at https://www.pcmag.com/encyclopedia/term/data-longevity
[242] Harrington LMB (2016) Sustainability Theory and Conceptual Considerations: A Review of Key Ideas for Sustainability, and the Rural Context. Papers in Applied Geography 2(4):365–382. 10.1080/23754931.2016.1239222
[243] Business model (2023) Wikipedia. Available at https://en.wikipedia.org/w/index.php?title=Business_model&oldid=1145556367
[244] Media (2020) Techopedia. Available at https://www.techopedia.com/definition/1098/media
[245] Integrity File, (2014) Techopedia. Available at https://www.techopedia.com/definition/30616/file-integrity
[246] Integrity CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/integrity
[247] What Are Advanced Search Options? Lifewire. Available at https://www.lifewire.com/what-are-advanced-search-options-3481444
[248] Data Preservation Network of the National Library of Medicine. Available at https://www.nnlm.gov/guides/data-glossary/data-preservation
[249] Backup (2022) Techopedia. Available at https://www.techopedia.com/definition/1056/backup
[250] Data recovery CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/data-recovery
[251] Data Archives and Why You Need Them Available at https://cloudian.com/guides/data-backup/data-archive/
[252] Deaccessioning and Disposal: Guidance for Archive Services (2015) Available at https://cdn.nationalarchives.gov.uk/documents/Deaccessioning-and-disposal-guide.pdf
[253] Data retention policy CODATA Research Data Management Terminology. Available at https://terms.codata.org/rdmt/data-retention-policy
[254] DataCite Support Best practices for tombstone pages. Available at https://support.datacite.org/docs/tombstone-pages
[255] Darwin Core Available at https://dwc.tdwg.org/
[256] Taillon JA, Bina TF, Plante RL, Newrock MW, Greene GR, Lau JW (2021) NexusLIMS: A Laboratory Information Management System for Shared-Use Electron Microscopy Facilities. Microscopy and Microanalysis 27(3):511–527. 10.1017/S1431927621000222
[257] PREMIS: Preservation Metadata Maintenance Activity (Library of Congress) Available at https://www.loc.gov/standards/premis/
[258] - Schema.org. Available at https://schema.org/
[259] ISO - Standards ISO. Available at https://www.iso.org/standards.html
[260] American National Standards Institute - ANSI Home American National Standards Institute - ANSI. Available at https://ansi.org/
[261] EUROPEAN COMMISSION Directorate-General for Research & Innovation (2016) H2020 Programme - Guidelines on FAIR Data Management in Horizon 2020. Available at https://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pilot/h2020-hi-oa-data-mgt_en.pdf
[262] Carroll SR, Garba I, Figueroa-Rodríguez OL, Holbrook J, Lovett R, Materechera S, Parsons M, Raseroka K, Rodriguez-Lonebear D, Rowe R, Sara R, Walker JD, Anderson J, Hudson M (2020) The CARE Principles for Indigenous Data Governance. Data Science Journal 19(1):43. 10.5334/dsj-2020-043
[263] Steer A, (2019) FAIRER Data. Spatialised. Available at https://www.spatialised.net/fairer-data/
[264] General Data Protection Regulation (GDPR) Compliance Guidelines Available at https://gdpr.eu/
[265] Research Data Management Framework for Institutions | ARDC (2023) https://ardc.edu.au/. Available at https://ardc.edu.au/resource/research-data-management-framework-for-institutions/
[266] RDA-OfR Mapping the digital research data infrastructure landscape WG Case Statement (2023) RDA. Available at https://www.rd-alliance.org/group/rda-ofr-mapping-digital-research-data-infrastructure-landscape-wg/case-statement/rda-ofr
[267] Murray V, Abrahams J, Abdallah C, Ahmed K, Angeles L, Benouar D, Brenes Torres A, Chang Hun C, Cox S, Douris J, Fagan L, Fra Paleo U, Han Q, Handmer J, Hodson S, Khim W, Mayner L, Moody N, Moraes LL, Osvaldo , Nagy , M, Norris , J, Peduzzi , P, Perwaiz , A, Peters , K, Radisch , J, Reichstein , M, Schneider , J, Smith , A, Souch , C, Stevance , A-S, Triyanti , A, Weir , M, Wright , N Hazard Information Profiles: Supplement to UNDRR-ISC Hazard Definition & Classification Review: Technical Report: (Geneva, Switzerland, United Nations Office for Disaster Risk Reduction; Paris, France, International Science Council., Geneva, Switzerland; Paris, France). Available at https://doi.org/10.24948/2021.05
[268] Deagen ME, McCusker JP, Fateye T, Stouffer S, Brinson LC, McGuinness DL, Schadler LS (2022) FAIR and Interactive Data Graphics from a Scientific Knowledge Graph. Scientific Data 9(1):239. 10.1038/s41597-022-01352-z
Appendix A : Informative References
Research data occupy a complex and vast space with formidable management challenges. While the RDaF seeks to offer a comprehensive view of research data management, organizations and individuals may identify additional topics, subtopics, and profiles germane to their specific circumstances. In addition to definitions for each topic and subtopic, the RDaF contains more than 800 informative references. Some informative references provide background information that enable a more in-depth understanding of a subtopic. Other informative references, such as guidelines, standards, and policies, aid a user in addressing a specific subtopic. The interactive web application described in section 2.3 will enable linkages of informative references to corresponding subtopics.
The entire bibliography of informative references is available at: https://doi.org/10.6028/NIST.SP.1500-18r1sup1
Appendix B : Descriptions of Key Organizations
This Appendix provides a list of many key organizations, each of which is accompanied by a short definition or description to provide some context of their role in research data management.
Academy of Science of South Africa - Officially recognized national science academy that aims to provide evidence-based scientific advice on issues of public interest to government and other stakeholders.
Accelerating Public Access to Research Data (APARD) - A collaboration between the Association of American Universities (AAU) and the Association of Public and Land-grant Universities (APLU) to improve public access to data resulting from federally funded research.
Alfred P. Sloan Foundation - This foundation makes grants primarily to support original research and education related to science, technology, engineering, mathematics, and economics.
American Geophysical Union (AGU) - An association of more than half a million advocates and professionals in Earth and space sciences.
American Library Association (ALA) - The oldest and largest library association in the world which aims to provide leadership for the development, promotion, and improvement of library and information services and the profession of librarianship to enhance learning and ensure access to information.
Association of American Medical Colleges - A not-for-profit association dedicated to transforming health through medical education, health care, medical research, and community collaborations.
Association of American Universities (AAU) - AAU’s 65 research universities transform lives through education, research, and innovation.
Association of Public and Land-grant Universities (APLU) - A membership organization of university leaders collectively working to advance the mission of public research universities. The association’s membership consists of more than 250 public research universities, land-grant institutions, state university systems, and affiliated organizations spanning all 50 states, the District of Columbia, four U.S. territories, Canada, and Mexico.
Association of Research Libraries (ARL) - A nonprofit membership organization of research libraries and archives in major public and private universities, federal government agencies, and large public institutions in Canada and the US.
Australian Research Data Commons (ARDC) - A leading research data infrastructure facility in Australia that accelerates Australian research and innovation by driving excellence in the creation, analysis and retention of high-quality data assets.
Belmont Forum - A partnership of funding organizations, international science councils, and regional consortia committed to the advancement of transdisciplinary science.
Bill & Melinda Gates Foundation - A foundation that funds multi-million dollar initiatives to support global programs aimed at improving the quality of life by advances in science, technology, and data.
Biodiversity Global Information Facility - An international network and data infrastructure funded by the world's governments and aimed at providing anyone, anywhere, open access to data about all types of life on Earth.
BRAIN Initiative - A collaborative, public-private research initiative funded by NIH with the goal of supporting the development and application of innovative technologies that can create a dynamic understanding of brain function.
California Digital Library - DMPTool - A free, open-source, online application that helps researchers create data management plans (DMPs).
CANAIRE - Formerly the Canadian Network for the Advancement of Research, Industry and Education, CANAIRE is the not-for-profit organization which operates the national backbone network of Canada's national research and education network (NREN).
Center for Open Science - A nonprofit organization that works to ensure that the process, content, and outcomes of research are openly accessible by default.
China Science and Technology Cloud - A national platform to provide scientists with efficient and integrated cloud solutions in the retrieval, access, use, transaction, delivery and other aspects of sharing scientific information and relevant services.
CKAN - An open-source data management system for powering data hubs and data portals. CKAN makes it easy to publish, share, and use data. It powers catalog.data.gov, open.canada.ca/data, and data.humdata.org, among many other sites.
Coalition for Publishing Data in the Earth and Space Sciences - A collaboration among research repositories, scholarly publishers, and other stakeholders focused on jointly developing, implementing, and promoting leading practices around the preservation and citation of data, software, and physical samples that lead toward credit and reuse in the Earth, space, and environmental sciences.
CENDI – CENDI is the Federal Scientific and Technical Managers Group. CENDI’s mission is to increase the impact of federally funded science and technology by improving the management and dissemination of U.S. federal scientific and technical information and data.
Committee on Data of the International Science Council (CODATA) - As the Committee on Data of the International Science Council (ISC), CODATA helps realize ISC’s vision of advancing science as a global public good. CODATA does this by promoting international collaboration to advance Open Science and to improve the availability and usability of data for all areas of research.
Commonwealth Scientific and Industrial Research Organisation (Australia) - An Australian Government agency that works with industry, government and the research community to turn science into solutions to address Australia's greatest challenges.
CoreTrustSeal - A nonprofit organization that promotes trustworthiness in repositories through certification.
Data Archiving and Networked Services (DANS, the Netherlands) - The Dutch national center of expertise and repository for research data.
DataCite - A leading global nonprofit organization that provides persistent identifiers (DOIs) for research data and other research outputs.
DataONE (Data Observation Network for Earth) - A community-driven program providing access to data across multiple member repositories, supporting enhanced search and discovery of Earth and environmental data.
Department of Energy (DOE) - The mission of the Department of Energy is to ensure America’s security and prosperity by addressing its energy, environmental, and nuclear challenges through transformative science and technology solutions.
Digital Research Alliance of Canada (DRAC) - DRAC serves Canadian researchers by integrating, championing, and funding the infrastructure and activities required for advanced research computing, research data management, and research software.
DKAN - A community-driven, free and open-source open data platform that gives organizations and individuals the ability to publish and consume structured information.
Dryad - A nonprofit membership organization that is committed to making data available for research and educational reuse now and into the future.
e-IRG – e-Infrastructure Reflection Group - A strategic body to facilitate integration in the areas of European e-infrastructures and connected services, within and between member states, at the European level and globally.
Earth Science Information Partners (ESIP) - Created by NASA, ESIP supports the networking and data dissemination needs of its members and the global Earth science data community by linking the functional sectors of observation, research, application, education and use of Earth science.
Economic Commission for Latin America and the Caribbean (ECLAC) - Headquartered in Santiago, Chile, ECLAC is one of the five regional commissions of the United Nations. It was founded with the purpose of contributing to the economic development of Latin America, coordinating actions directed towards this end, and reinforcing economic ties among countries and with other nations of the world.
European Data Infrastructure (EUDAT) - One of the largest infrastructures of integrated data services and resources supporting research in Europe.
European Open Science Cloud (EOSC) - An environment for hosting and processing research data to support EU science.
European Strategy Forum on Research Infrastructures (ESFRI) - A group that supports a coherent and strategy-led approach to policy making on research infrastructures in Europe, and facilitates multilateral initiatives leading to the better use and development of research infrastructures at the EU and international level.
FAIRsharing.org - A community-driven resource with users and collaborators across all disciplines who work together to enable the FAIR Principles by promoting the value and the use of standards, databases and policies.
Fedora Commons - A digital asset management content repository architecture upon which institutional repositories, digital archives, and digital library systems might be built.
Figshare - A repository where users can make all their research outputs available in a citable, shareable and discoverable manner.
Flatiron Institute - An internal research division of the Simons Foundation, the institute is a community of scientists who are working to use modern computational tools to advance science, both through the analysis of large, rich datasets and through the simulations of physical processes.
Future of Research Communications and e-Scholarship (FORCE11) - A community of scholars, librarians, archivists, publishers and research funders that aims to help facilitate the change toward improved knowledge creation and sharing.
Global Dataverse Community Consortium (GDCC) – An international organization for existing and new Dataverse community efforts that provides a collaborative venue for institutions to leverage economies of scale in support of Dataverse repositories around the world.
Global Open Findable, Accessible, Interoperable and Reusable (GO FAIR) - A community working towards implementations of the FAIR Guiding Principles. This collective effort has resulted in a three-point framework that formulates the essential steps towards the end goal, a global Internet of FAIR Data and Services.
Harvard Dataverse - A free data repository open to all researchers from any discipline, both inside and outside the Harvard community, where one can share, archive, cite, access, and explore research data.
Higher Education Leadership Initiative for Open Scholarship (HELIOS) - A cohort of colleges and universities committed to collective action to advance open scholarship within and across their campuses.
Integrated Global Greenhouse Gas Information System - An observation-based information system for determining trends and distributions of greenhouse gasses (GHGs) in the atmosphere and the ways in which they are consistent or not with efforts to reduce GHG emissions.
International Association of Scientific, Technical and Medical Publishers (STM) - The leading global trade association for academic and professional publishers.
International Bureau of Weights and Measures (BIPM) - An international organization established by the Metre Convention, through which Member States act together on matters related to measurement science and measurement standards.
International Council for Scientific and Technical Information (ICSTI) - A specialized intergovernmental organization established for ensuring the international exchange of scientific and technical information.
International Development Research Center (Canada) - A Canadian government project that funds research and innovation within and alongside developing regions to drive global change.
International Federation of Library Associations (IFLA) - An international organization that works to represent the interests of the librarian profession and improve services worldwide.
International Science Council (ISC) - Works at the global level to catalyze and convene scientific expertise, advice and influence on issues of major concern to both science and society.
Inter-university Consortium for Political and Social Research (ICPSR) – An organization that supports research by maintaining an archive of disciplinary research and offering training in the use of data.
Islandora - A foundation that maintains an extensible, modular, open-source digital repository ecosystem focused on collaborative authorship, management, display, and preservation of digital content at scale.
Kavli Foundation - A foundation that aims to advance science for the benefit of humanity by: stimulating basic research in the fields of astrophysics, nanoscience, neuroscience, and theoretical physics; strengthening the relationship between science and society; and honoring scientific discoveries.
Laura and John Arnold Foundation - A philanthropic organization dedicated to improving the lives of all Americans through evidence-based policy solutions that maximize opportunity and minimize injustice.
Materials Genome Initiative - A federal multi-agency initiative for discovering, manufacturing, and deploying advanced materials twice as fast and at a fraction of the cost compared to traditional methods. The initiative creates policy, resources, and infrastructure to support U.S. institutions in the adoption of methods for accelerating materials development.
National Academies of Sciences, Engineering, and Medicine (NASEM) - A nonprofit organization that provides independent, objective advice to inform policy with evidence, spark progress, and drive innovation.
National Aeronautics and Space Administration (NASA) – An independent agency of the U.S. federal government responsible for the civil space program, aeronautics research, and space research.
National Information Standards Organization (NISO) - A non-profit standards organization that develops, maintains, and publishes technical standards related to publishing, bibliographic, and library applications.
National Institute of Standards and Technology (NIST) - A United States federal agency whose mission is to promote innovation and industrial competitiveness by advancing measurement science, standards, and technology in ways that enhance economic security and improve quality of life.
National Institutes of Health (NIH) - Part of the U.S. Department of Health and Human Services, NIH is the largest biomedical research agency in the world.
National Library of Medicine (NLM) - The world’s largest biomedical library, NLM maintains and makes available a vast print collection and produces electronic information resources on a wide range of topics.
National Science and Technology Council (NSTC) - A cabinet-level council of advisers to the President on science and technology that includes the Subcommittee on Open Science, formerly the Interagency Working Group on Open Science.
NOIRLab - NSF's NOIRLab, formerly named the National Optical-Infrared Astronomy Research Laboratory, is the United States national center for ground-based, nighttime optical astronomy.
ORCID (Open Researcher and Contributor ID) - A global, not-for-profit organization providing a unique, persistent identifier for individuals to use as they engage in research, scholarship, and innovation activities.
Organization for Economic Co-operation and Development (OECD) - An international organization that works with governments, policy makers, and citizens, on establishing evidence-based international standards and finding solutions to a range of social, economic, and environmental challenges.
Pub Med Central - A free digital repository run by the National Institutes of Health (NIH) that archives open-access full-text scholarly articles that have been published in biomedical and life sciences journals.
re3data (Registry of Research Data Repositories) - A global registry of research data repositories from all academic disciplines.
Research Data Alliance (RDA) - Launched as a community-driven initiative in 2013 by the European Commission, the United States Government's National Science Foundation and National Institute of Standards and Technology, and the Australian Government’s Department of Innovation, RDA has the goal of building the social and technical infrastructure to enable open sharing and reuse of data.
São Paulo Research Foundation (Brazil) - A public foundation located in São Paulo, Brazil, with the aim of providing grants, funds, and programs to support research, education, and innovation of private and public institutions and companies in the state of São Paulo.
Scholarly Publishing and Academic Resources Coalition (SPARC) - A non-profit advocacy organization that supports systems for research and education that are open by default and equitable by design.
Society for Scholarly Publishing (SSP) - A nonprofit organization formed to promote and advance communication among all sectors of the scholarly publication community through networking, information dissemination, and facilitation of new developments in the field.
Wellcome Trust - A global charitable organization that supports discovery research into life, health and wellbeing, with a focus on three worldwide health challenges: mental health, infectious disease and climate and health.
World Data System (WDS) - An affiliated body of the International Science Council (ISC) that aims to enhance the capabilities, impact and sustainability of member data repositories and data services.
Zenodo - An open repository developed under the European OpenAIRE program and operated by European Organization for Nuclear Research (CERN) that enables researchers to preserve and share their research output from any science, regardless of the size and format.
Appendix C : Acronyms and Initialisms
- AAU
- Association of American Universities
- AGU
- American Geophysical Union
- AI
- artificial intelligence
- APARD
- Accelerating Public Access to Research Data
- API
- Application programming interface
- APLU
- Association of Public and Land-grant Universities
- ARK
- Archival Resource Key
- C-Suite
- Corporate suite
- CARE
- Collective benefit, Authority to control, Responsibility, and Ethics
- CDO
- Chief Data Officer
- CE
- critically evaluated
- CENDI
- Federal Scientific and Technical Information Managers Group (formerly Commerce, Energy, NASA, Defense Information Managers Group)
- CEO
- Chief Executive Officer
- CODATA
- Committee on Data of the International Science Council
- CPU
- central processing unit
- CRediT
- Contributor Roles Taxonomy: used to represent the roles typically played by contributors to scientific scholarly output
- DMP
- data management plan
- DOC
- Department of Commerce
- DOE
- Department of Energy
- DOI
- digital object identifier
- FAIR
- Findable, Accessible, Interoperable, and Reusable
- HPC
- high-performance computing
- HR
- human resources
- IDE
- Interactive Development Environment: an application that provides a full suite of features to facilitate software development that typically allow a programmer to code, debug, and preview the effect of their code.
- IP
- intellectual property
- IT
- information technology
- LIMS
- Laboratory Information Management System
- ML
- Machine Learning
- NASEM
- National Academies of Sciences, Engineering, and Medicine
- NIST
- National Institute of Standards and Technology
- NSF
- National Science Foundation
- ORCID
- Open Researcher and Contributor ID
- OSTP
- Office of Science and Technology Policy
- PIDINST
- Persistent Identifiers of Instruments
- PII
- Personally Identifiable Information
- RDA
- Research Data Alliance
- RDaF
- Research Data Framework
- ROR
- Research Organization Registry: unique identifiers for every research organization in the world
- SPARC
- Scholarly Publishing and Academic Resources Coalition
Appendix D : Sample Profiles (Supplementary Document)
Sample profiles for eight common research data management job roles are available as a supplementary document at https://doi.org/10.6028/NIST.SP.1500-18r1sup2 and on the RDaF homepage. This document contains the information in Section 5 and provides a blank template in a format amenable to the generation of customized profiles.
Appendix E : Change Log
In Fall 2023, the following updates were made to the published RDaF preliminary version 1.0 to produce this full version 2.0:
-
Expanded the topics and subtopics in the lifecycle stages which make up the “framework core,” renamed the “framework foundation”
-
Added 14 overarching themes, that are pervasive throughout the lifecycle stages
-
Added eight sample profiles, each of which identifies those topics and subtopics that are most relevant to a common job role or function in research data management
-
Added definitions for the topics and subtopics
-
Added informative references, such as guidelines, standards, and policies, for most of the subtopics
-
Developed and released an interactive web application RDaF V2.0 that replicates the content of the V2.0 document
-
Added a methodology section that describes the means by which the framework was updated
-
Added ongoing work